
생각 작업실 The atelier of thinking
6. 자료 수집 - 표본 추출 (Sampling) 본문
Chapter 6. 자료 수집 - 표본추출(Sampling)
1. 표본 추출 개념
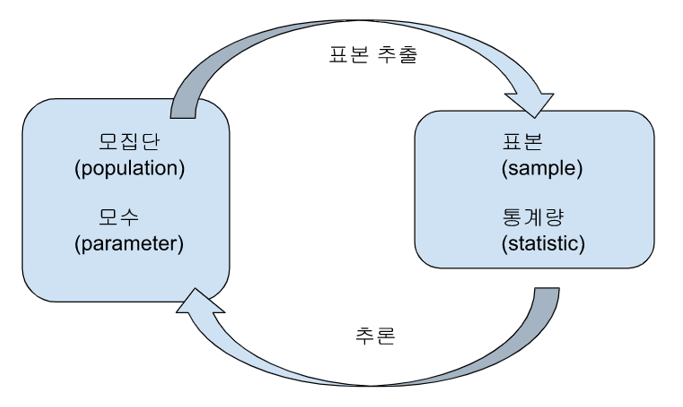
통계학은 관심 또는 연구의 대상인 모집단의 특성을 파악하기 위해,
모집단으로부터 일부의 자료(표본)를 수집하고
수집된 표본을 정리, 요약, 분석하여 표본의 특성을 파악한 후
표본의 특성을 이용하여 모집단의 특성에 대해 추론하는 원리와 방법을 제공하는 학문입니다.
표본추출은 통계학의 시작이라고 할 수 있습니다. 모집단으로부터 일부의 자료인 표본을 추출하여 해당 표본을 대표할 수 있도록 잘 선택하는 것이 중요합니다.
만약 표본추출이 잘못되어 적절하지 않은 표본이 선택된다면, 해당 표본을 기반으로 한 모집단에 대한 추론은 틀릴 수 밖에 없습니다. 따라서 표본추출은 통계적 분석을 수행하는 데 있어 가장 기본이 되는 요소라고 할 수 있습니다.
표본추출 방법은 다양하며, 각각의 방법에 따라 선택된 표본이 어떤 특성을 갖게 될 지 결정됩니다. 예를 들어, 단순랜덤추출, 층화추출, 집락추출 등이 있으며, 이러한 방법들을 적절하게 사용하여 표본을 추출해야 합니다.
또한, 표본의 크기도 중요한 문제입니다. 표본의 크기가 작으면 모집단을 대표할 수 없을 뿐만 아니라, 통계적으로 유의한 결과를 얻기 어렵습니다. 따라서 표본의 크기는 충분히 크게 설정해야 합니다.
결론적으로, 표본추출은 모집단에 대한 정확한 추론을 위해 매우 중요한 역할을 합니다. 통계학을 공부하는 데 있어서 표본추출에 대한 이해는 필수적입니다.

위 그림을 PPDAC 로 나타내면,
① Problem - 모집단 I 은 어떤 특성을 가지고 있을까?
② Plan - 표본을 어떻게 추출할 것인가?
③ Data - 표본추출로 얻어진 데이터 수집
④ Analysis - 통계적 추론 등을 통해 데이터 분석
⑤ Conclusion - 모집단 II 의 특성을 확인한다.
2. 표본 추출을 하는 이유
경제학,경영학, 사회과학, 인문과학, 법학, 의학, 공학, 자연과학 등 분야를 막론하고 통계학을 사용합니다.
우리는 통계에 묻혀 산다고 할 수 있습니다.
주변에서 특히 뉴스 등에서 볼 수 있는 통계와 관련된 기사들을 예시해 보면,
▶ 10% 담배값 인상이 청소년층의 흡연을 어느 정도 줄이나?
▶ 직업훈련은 재 취업률을 높이는가 ? 임금률에 미치는 효과는 ?
▶ 외국인 직접투자가 늘면 경제 성장률이 제고되는가?
▶ 특정 광고가 매출증가 효과를 가져왔는가?
▶ 노동시장에서 여성에 대한 차별이 존재하는가?
위 예시의 질문들에 대해 확실하게 아는 방법은 모든 대상을 조사, 즉 전수조사를 하면 확실히 알겠지만, 전수조사를 못하는 경우가 많습니다. 대부분의 이유는 비용과 시간이 너무 많이 들기 때문일 것입니다. 이 때 필요한 것이 표본을 추출해서 즉 일부만 선택해서 조사하는 것입니다.
3. 표본의 대표성
모집단으로부터 표본을 뽑을 때 가장 중요하게 살펴봐야 하는 것이 이 표본을 뽑을 때 전체(모집단)를 잘 반영할 수 있게 뽑아야 한다는 것입니다. 즉, 표본이 모집단을 대표할 수 있어야 하는 것입니다.
표본의 대표성이 중요한 것을 알려주는 사례로 " 1936년 미국 대통령선거 결과 예측" 이 있습니다.
★★★ 1936년 미국 대통령 선거 예측 ★★★
1936년 미국 대통령 선거에는 공화당에서는 Landon 후보가, 민주당은 Roosevelt 후보가 각각 출마하였다고 합니다.

Literary Digest 라는 잡지는 1916 ~ 1932년의 대통령 선거 결과를 정확하게 예측한 경험이 있었다고 합니다. 이 회사는 그 당시 규모도 크고 이 잡지의 구독자, 전화기 및 자동차 보유자 236만 여명의 의견을 분석하여 나온 결과는 Landon 57%, Roosevelt 43%로 공화당의 Landon 후보의 당선을 예측하였다고 합니다.

반면, 당시 신생회사였던 Gallup(갤럽)은 단순 무작위 표본으로 5만명을 조사하여 나온 결과는 공화당 Landon 후보는 44%, 민주당Roosevelt 후보는 56%로 Roosevelt 후보의 당선을 예측하였다고 합니다. 심지어 갤럽은 Digest(다이제스트)가 루즈벨트 후보에 대하여 44%로 예측 할 것이라고 예측하였다고 합니다.
결과는 Roosevelt 63%, Landon 37%로 루즈벨트 후보가 당선되었습니다.
이를 계기로 'Literary Digest' 는 쇠락의 길을 걸었고, Gallup(갤럽)은 급성장하며 오늘날 여론 조사의 대명사가 되었다고 합니다.
'Literary Digest'의 실패 원인을 살펴보면,
표본추출방식에 심각한 문제가 있었습니다. 표본의 숫자가 크면 좋은 것이라 생각해 236만이라는 많은 수의 여론조사를 시행했는데, 당시 전화기 및 자동차 보유자는 부자들만이 가능한 일이었다고 합니다. 그렇다보니 부자들만의 여론조사를 했다고 볼 수 있습니다. 즉, "대표성"에서 심각한 오류가 발생했고 잘못된 결과가 나올 수 밖에 없는 상황이 되어 버린 것입니다.
반면 Gallup은 5만명의 단순 무작위 표본으로 대표성 있게 표본을 뽑아 시행하였고, 표본 중 다이제스트사가 중점을 두었던 부유층 부분만 따로 분석하여 그들의 예측까지 예측할 수 있었습니다.
이 1936년 미국 대통령 선거 여론조사는 대표성을 가진 표본 추출이 얼마나 중요한 지를 알려주는 사례라고 할 수 있습니다.
'통계학 이야기' 카테고리의 다른 글
| 8. 자료 수집 - 표본 편의(Sampling Bias) (0) | 2023.08.25 |
|---|---|
| 7. 자료 수집 : 표본 추출 방법 (1) | 2023.08.22 |
| 5. 자료 수집 - 통계적 실험과 관측 연구 (0) | 2023.08.22 |
| 4. 통계분석과 자료 (Data) (0) | 2023.08.22 |
| 3. 통계 분석 이란 ? (0) | 2023.08.07 |



