
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- css
- 확률
- 이원배치 분산분석
- 가설검정
- 산점도
- 해운업
- 티스토리챌린지
- 고정효과모형
- 경제학
- JavaScript
- version 2
- html
- 혼합효과모형
- 이항분포
- 에세이
- 반복있음
- 글쓰기
- 통계학
- 정규분포
- version 1
- r
- 회귀분석
- 변동분해
- 분산분석
- 데이터 과학
- 반복없음
- 추정
- 변량효과모형
- 오블완
- 인공지능
- Today
- Total
생각 작업실 The atelier of thinking
52. R을 이용한 확률분포 - 정규분포 구하기 본문
Chapter 52. 정규분포(Normal Distribution) 구하기
1. R 에서의 확률분포
| 이산확률분포 | 연속확률분포 | ||
| 이항분포 | binom | 정규분포 | norm |
| 초기하분포 | hyper | T분포 | t |
| 포아송분포 | pois | F분포 | f |
| 기하분포 | geom | 카이분포 | chisq |
| 음이항분포 | nbionom | 균등분포 | unif |
| 다항분포 | multinom | 지수분포 | exp |
구하고자 하는 함수에 따라 아래의 접두사를 붙여 사용하면 됩니다.
- d : probability mass/density function - 확률 질량/밀도 함수
- p : cumulative distribution function - 누적함수
- q : quantile function - 분위수
- r : random number generator - 램덤 생성 작업
2. 정규분포
정규분포의 확률밀도 함수는 아래와 같습니다.
$$f(x)=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}} , - \infty < x < \infty $$
R에서 정규분포 확률밀도함수를 구하는 함수는 'dnorm' 입니다.
dnorm(x, mean= , sd= )
x : 계산하려는 확률밀도함수의 위치
mean : 정규분포의 평균
sd : 정규분포의 표준편차
x <- c(1,2,3)
dnorm(x, mean = 0, sd = 1)[1] 0.241970725 0.053990967 0.004431848
위 코드는 평균이 0, 표준편차가 1 인 표준정규분포입니다.
나온 값은 그래프에서 높이(밀도) 입니다.
확률밀도함수 그래프 - plot
x <- seq(-3, 3, by = 0.1)
y <- dnorm(x, mean = 0, sd = 1)
plot(x, y, type = "l", col = "blue", lwd = 2, main = "Normal Distribution")
abline(h=0)
curve( ) 함수를 사용하여 정규분포곡선을 그려보겠습니다.
cruve(func, from = , to = , ...)
func : 그래프를 그리기 위한 함수
from : 함수의 시작 범위
to : 함수의 끝 범위
curve(dnorm,-3,3,ylab="f(x)",col="blue",lwd = 2, main = "Normal Distribution")
abline(h=0)
points(1,dnorm(1,0,1),col="red",pch=16)
points(2,dnorm(2,0,1),col="red",pch=16)
curve( ) 함수로 그린 그래프 위에 1과 2 일 때의 확률밀도함수 값을 점으로 표시해 봤습니다.
▶ lines( ) 함수는 산점도나 선 그래프 등 추가적인 선을 그리는 데 사용합니다.
curve(dnorm,-3,5,ylab="f(x)",col='blue',lwd = 2)
abline(h=0)
x <- seq(-3,5,by=0.01)
lines(x,dnorm(x,1.5,1),col="red",lwd = 2)
abline(v=c(0,1.5),col="green",lty=3)
위 그래프는 분산은 같고, 평균이 다른 정규분포들을 표현한 것입니다.
3. 정규분포의 확률 계산
연속확률변수 한 점에서의 확률은 0이 나오기 때문에 확률계산은 구간으로만 할 수 있습니다.
정규분포의 확률계산을 위해 필요한 함수는 'pnorm' 입니다.
pnorm(x, mean= 0, sd= 1, lower.tail = TRUE)
x : 확률변수가 어떤 값보다 작거나 같은 확률을 계산
mean : 정규분포의 평균값, 기본값은 0
sd : 정규분포의 표준편차, 기본값은 1
lower.tail : 누적분포함수의 방향을 구분하여 계산합니다.
TRUE인 경우는 왼쪽 끝부터 x까지의 확률
FALSE인 경우는 오른쪽 끝부터 x까지의 확률
▶ $ P ( Z < 1.96 ) $ 인 경우의 확률
pnorm(1.96)
pnorm(1.96,mean=0,sd=1,lower.tail = TRUE)[1] 0.9750021
▶ $ P (0 < Z < 1.2 ) $ 인 경우의 확률
pnorm(1.2)-pnorm(0.5)
▶ $ P ( Z > 1.2 ) $ 인 경우의 확률
pnorm(1.2, lower.tail = FALSE)
1-pnorm(1.2)[1] 0.1150697
▶ 표준정규분포표
x <- seq(0,1.99,by=0.01)
Fx <- pnorm(x)
Fx <- matrix(Fx,20,10,byrow=T)
Fx <- round(Fx,4)
colnames(Fx) <- 0:9
rownames(Fx) <- seq(0,1.9,by=0.1)
Fx 0 1 2 3 4 5 6 7 8 9
0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359
0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753
0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141
0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517
0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879
0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224
0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549
0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852
0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
1 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621
1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830
1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015
1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319
1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441
1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545
1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633
1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9761 0.9767
4. 정규분포의 성질
두 정규확률변수의 선형 결합도 정규분포를 따릅니다.
$$ X_1 \backsim N(\mu_1, \sigma_1^{2}) 이고, X_2 \backsim N(\mu_2, \sigma_2^{2}) 이면, $$
$$ X_1 \pm X_2 \backsim N( \mu_1+\mu_2 , \sigma_1^2+\sigma_2^2 \pm 2\sigma_{12}) $$
만약 두 정규확률변수가 독립이면, 공분산이 0 이므로,
$$ X_1 \pm X_2 \backsim N( \mu_1+\mu_2 , \sigma_1^2+\sigma_2^2 ) $$
◈ 예제 : 아침식사로 빵과 우유만 먹는다고 가정하고 둘은 독립이라고 했을 때,
빵의 열량은 $X \backsim N(200,144)$ 인 정규분포를 따르고,
우유의 열량은 $ Y \backsim N(85,81)$ 인 정규분포를 따른다고 합니다.
(1) 이 때 하루 300kcal 이상을 섭취할 확률은 ?
정규분포의 성질에 따라 $X+Y$ 는 정규분포를 따르게 됩니다.
따라서, $ X+Y \backsim N( 200+85 , 12^2+9^2) $일 때, $P(X+Y>300)$ 을 구하는 코드를 작성하면 됩니다.
mu <- 200+85
sigma <- sqrt(12^2 + 9^2)
pnorm(300,mu,sigma,lower.tail = F)
[1] 0.1586553
(2) 동일한 식사를 일주일 했을 때, 300kcal 이상 섭취할 날이 하루일 확률은 ?
이 경우는 이항분포를 사용해야 합니다. 이 때 사용할 확률은 위 문제에서 구한 확률을 사용합니다.
n <- 7
p <- 0.1587
dbinom(1,n,p)[1] 0.3938948
(3) 아침식사 칼로리에 대한 통계모델
통계모델을 만들 때 중점을 두는 것이 무작위성입니다. 무작위로 선택된 표본이나 실험결과가 모집단을 대표한다는 가정을 하기 때문에 무작위성을 발생시키는 난수는 통계실험에서 많이 사용됩니다.
정규분포에서 난수를 생성할 때는 'rnorm' 을 사용합니다.
mu <- 200+85
sigma <- sqrt(12^2 + 9^2)
n <- 100000
x <- rnorm(n,200,12)
y <- rnorm(n,85,9)
cal <- x+y
hist(cal,nclass=50,main="아침식사 칼로리",prob=T)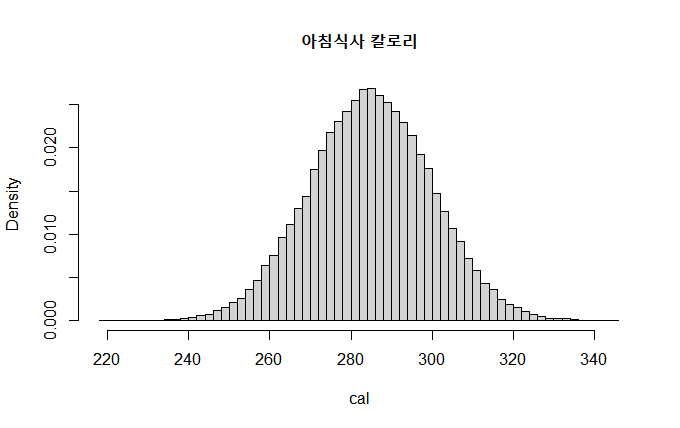
10만번의 난수발생으로 실행된 결과입니다. 매번 실행할 때마다 조금씩 변하는 것을 볼 수 있습니다.
z <- seq(230,350,by=0.1)
lines(z,dnorm(z,mu,sigma),col="blue",lwd=2)
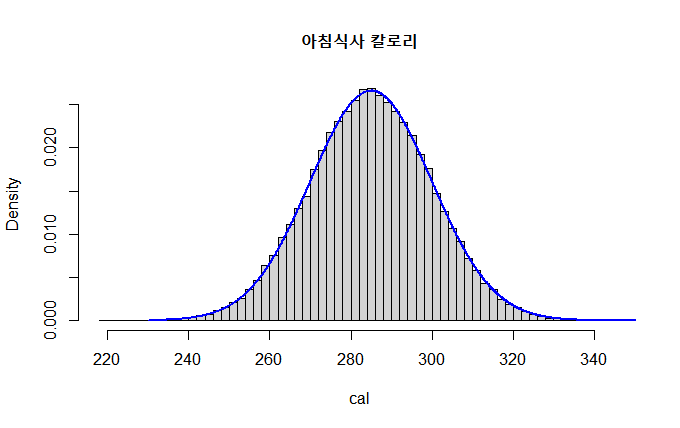
정규분포곡선을 히스토그램 위에 추가했을 때 거의 일치함을 볼 수 있습니다.
'통계학 이야기' 카테고리의 다른 글
| 54. 표집분포와 대수의 법칙 그리고 중심극한정리 (0) | 2023.11.20 |
|---|---|
| 53. 표집분포와 확률표본 그리고 통계량 (0) | 2023.11.16 |
| 52. 정규분포(Normal Distribution) - 연속확률분포 (1) | 2023.11.14 |
| 51. R을 이용한 확률분포 - 다항분포 구하기 (1) | 2023.11.03 |
| 50. 다항분포(Multinomial Distribution) - 이산확률분포 (0) | 2023.11.02 |



