
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 가설검정
- 인공지능
- 분산분석
- 변동분해
- 혼합효과모형
- version 2
- 이항분포
- 변량효과모형
- 에세이
- version 1
- 추정
- 오블완
- 정규분포
- 확률
- 해운업
- JavaScript
- 산점도
- html
- 데이터 과학
- 통계학
- css
- 경제학
- 반복있음
- 글쓰기
- r
- 회귀분석
- 반복없음
- 고정효과모형
- 이원배치 분산분석
- 티스토리챌린지
- Today
- Total
생각 작업실 The atelier of thinking
65. 모평균에 대한 통계적 추론 II 본문
Chapter 65. 모평균에 대한 통계적 추론 II
기본적으로 통계학 추론을 할 때에는 모집단에 대한 가정이 있는지 없는지 또는 그 가정이 만족하는지 안 하는지에 대해서 체크해야 합니다.
앞서 모집단이 정규분포라 가정한 통계적 추론 과정을 알아봤습니다.
모집단이 정규분포를 따른다고 가정했을 때에는 T분포를 이용하여 추론이 가능합니다.
이번 회차에서는 모집단이 정규성을 만족하지 않을 때에 통계적 추론 방법에 대해서 알아보겠습니다.
표본 크기가 클 때와 표본 크기가 크지 않고 이상점이 존재할 때로 나누어 살펴보겠습니다.
1. 모집단이 정규성을 만족하지 않고 표본크기가 클 때
표본크기가 큰 경우이면 중심극한정리에 의해 정규분포에 근사합니다.따라서, 정규분포를 가정하고 통계적 추론을 합니다.
검정 통계량은 표준 정규 분포에 근사하게 됩니다.
$$\bar{X} \backsimeq N(\mu ,\frac{\sigma ^2}{n})$$
$$Z_0 = \frac{\overline {X}-\mu }{S/\sqrt{n}} \backsimeq N( 0, 1 ) $$
다만, 표본 크기가 크다는 기준에 대해서는 명확하지는 않습니다. 일반적으로 표본크기(n)가 30 이상이면 대표본으로 정규분포에 근사한다고 간주하지만, 모든 경우가 적용되지는 않습니다.
(1) 구간 추정
통계적 추론의 방법 중 하나인 구간추정은 정규분포를 가정하고 아래와 같이 할 수 있습니다.
$$( \overline {X}-Z_{\alpha /2}S/\sqrt{n},\ \overline {X}+Z_{\alpha /2}S/\sqrt{n})$$
◈ 예제 : A 담배에 포함된 평균 니코틴 함유량
100개의 A 담배를 임의 추출하여 조사한 결과 평균함유량이 0.53mg, 표준편차는 0.11mg 라고 할 때, 실제 평균 니코틴에 대한 95% 신뢰구간은 ?
⇒ 표본이 100개 이므로 대표본이라 보고 중심극한정리에 의해 정규분포에 근사한다는 가정하에 정규분포에서의 구간 추정을 이용합니다.
$$\left(0.53-1.96\times \frac{0.11}{\sqrt{100}}\ ,\ 0.53+1.96\times \frac{0.11}{\sqrt{100}}\right)$$
$$=\left(0.508,\ 0.552\right)$$
(2) 가설 검정
통계적 추론의 방법 중 하나인 가설검정은 아래와 같이 할 수 있습니다.
◈ 예제 : A 담배에 포함된 평균 니코틴 함유량
소비자단체에서 A담배에 포함된 니코틴 함유량이 표지에 표기된 0.5mg보다 많다고 주장합니다. 이 때 니코틴 함유량 평균이 표기된 것보다 많은지를 5% 유의수준에서 검정한다면?
⇒ 이 경우 귀무가설은 "니코틴 함유량이 5mg보다 같거나 작다." 로
대립가설은 "니코틴 함유량이 5mg보다 크다." 라고 할 수 있습니다.
$$ H_0 : \mu \ =0.5\ \ vs\ \ H_1\ :\ \mu \ >\ 0.5$$
▶ 검정통계량
$$z=\frac{0.53-0.5}{0.11/\sqrt{100}}\ =2.727$$
5% 유의수준에서의 분위수는 1.645 입니다.
▶ 비교
$$2.727\ >\ 1.645 $$
귀무가설 기각. 따라서, 5% 유의수준에서 니코틴의 함유량이 표시된 니코틴 양보다 많다고 할 수 있습니다.
▶ P-value
$$P\left(Z\ >\ 2.727\right)\ =\ 0.003$$
2. 표본크기가 크지 않고 이상점이 존재할 때
표본크기가 크지 않고 이상점이 존재할 때는 비모수적 방법을 사용합니다.
비모수적 추론은 모집단의 분포를 가정하지 않고, 분포의 형태와 모수를 추정하지 않고 직접 표본 데이터를 이용하여 추론하는 방법입니다. 모집단이 어떤 분포를 따르는지 모르는 경우에 적용가능합니다.
분포에 대한 제한 조건은 없으며, 중심위치에 대한 검정방법입니다.
(1) 부호 검정 (Sign Test)
부호검정이란 모집단의 중앙값에 대한 검정 방법으로 관찰된 표본 중에서 중앙값을 초과하는 것이 몇 개인지 파악하는 것으로 검정을 합니다.
◈ 예제 : 통계학 관련학과 대학 정보 공시 취업률 자료
55.6 83.3 43.4 58.1 31.6 55.6 60.7 64.6 73.3 55.6 64.3
52.8 22.7 46.3 71.4 53.8 64.5 67.9 71.4 80.0 59.5 40.5
77.1 58.6 65.4 52.4 66.7 91.3 41.3 72.1 61.9 78.4 63.6
41.0 65.2 81.3 54.8 19.6 50.0 53.1 41.2 56.5
위 자료는 통계학 관련 42개 학과의 취업률을 나타내고 있습니다.
해당 연도 전체 대졸 취업률은 54.5% 정도가 된다고 할 때, 위 통계학 관련학과 취업률 평균이 전체 취업률보다 높다고 할 수 있을까?
⇒ 부호검정을 이용하였을 때, 총 42개 학과 중 28개 학과가 54.5% 보다 높게 나타납니다.
이 때, p-value = 0.028 입니다.
(2) Wilcoxon 부호검정 (Wilcoxon Signed Rank Test)
부호검정은 위치만 파악할 뿐 크기를 고려하지 않습니다. 이를 보완 하기 위한 검정으로 Wilcoxon 부호검정이 있습니다. Wilcoxon 부호검정은 작은 거리부터 순위를 매기고 왼쪽은 " - " 를 오른쪽은 "+"로 주고 더한 값으로 검정을 합니다.
◈ 예제 : 통계학 관련학과 대학 정보 공시 취업률 자료
55.6 83.3 43.4 58.1 31.6 55.6 60.7 64.6 73.3 55.6 64.3
52.8 22.7 46.3 71.4 53.8 64.5 67.9 71.4 80.0 59.5 40.5
77.1 58.6 65.4 52.4 66.7 91.3 41.3 72.1 61.9 78.4 63.6
41.0 65.2 81.3 54.8 19.6 50.0 53.1 41.2 56.5
해당 연도 전체 대졸 취업률은 54.5% 정도가 된다고 할 때, 위 통계학 관련학과 취업률 평균이 전체 취업률보다 높다고 할 수 있을까?
⇒ Wilcoxon 부호검정을 이용하였을 때, 검정값은 "양의 부호 순위합 = 604, p-value = 0.0287" 의 결과가 나옵니다.
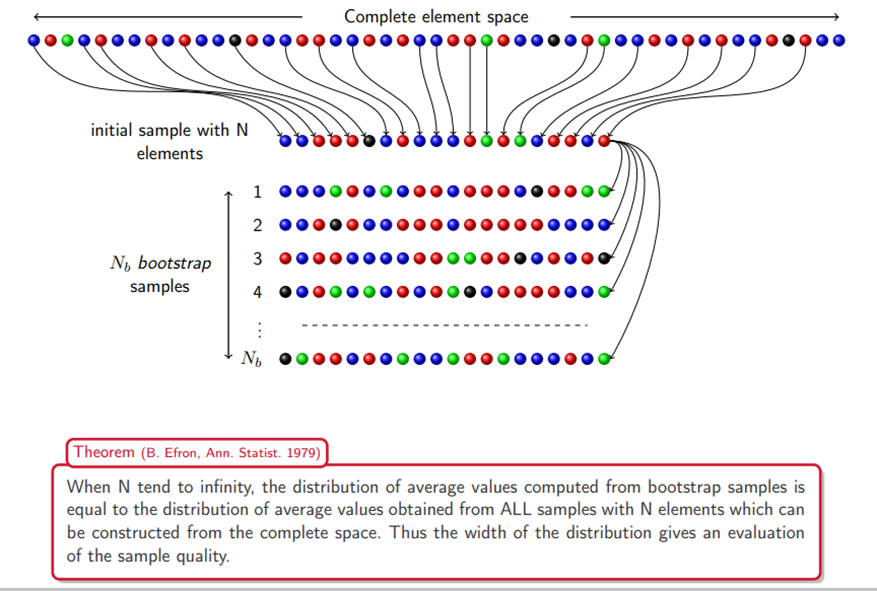
3. 부트스트래핑(Bootstrapping)
부트스트래핑(Bootstrapping)은 통계학에서 주어진 표본 데이터셋으로부터 재표집(resampling)을 통해 표본 분포를 추정하고, 이를 이용하여 추정량의 특성을 평가하는 비모수적인 방법입니다.
일반적으로 통계적 추정이나 가설 검정을 수행할 때, 모집단의 분포나 특성에 대한 가정을 필요로 합니다. 그러나 모집단에 대한 정보가 부족하거나 모집단 분포가 알려지지 않은 경우가 많습니다. 부트스트래핑은 이러한 상황에서 모집단 분포에 대한 가정을 하지 않고도 표본 데이터를 이용하여 추정량의 분포를 추정할 수 있는 방법을 제공합니다.
부트스트래핑의 주요 단계는 다음과 같습니다.
(1) 재표집(Resampling)
주어진 표본 데이터셋으로부터 복원 추출(With Replacement) 방식을 사용하여 동일한 크기의 여러 개의 재표본을 생성합니다.
(2) 통계량 계산
각 재표본에 대해 원하는 통계량(예: 평균, 분산 등)을 계산합니다.
(3)추정 분포 구성
통계량 계산을 통해 얻은 값들을 이용하여 추정 분포를 구성합니다.
(4) 추정 및 신뢰 구간
추정 분포를 이용하여 추정량의 평균이나 신뢰 구간을 계산합니다.
부트스트래핑은 특히 모집단의 분포가 정규분포가 아닌 경우에도 유용하게 활용될 수 있습니다. 또한, 신뢰구간의 추정이나 통계량의 표준 오차(standard error) 등을 계산하는 데에도 사용됩니다. 부트스트래핑은 비모수적인 방법이기 때문에 모집단의 분포에 대한 가정이 필요 없으며, 보다 일반적인 상황에서도 유연하게 적용될 수 있습니다.
▶ Bootstapping 원리

출처 : https://inferentialthinking.com/chapters/13/2/Bootstrap.html
13.2. The Bootstrap — Computational and Inferential Thinking
13.2. The Bootstrap A data scientist is using the data in a random sample to estimate an unknown parameter. She uses the sample to calculate the value of a statistic that she will use as her estimate. Once she has calculated the observed value of her stati
inferentialthinking.com
원래는 모집단(population)에서 표본(sample)을 여러 개 뽑는 것이지만, 여러 사정상 그럴 수 없다면 뽑아놓은 표본(sample)을 여러 번 복원추출하여 통계량을 구하는 방법입니다.
표본(sample)에서 복원추출을 하기 때문에 중복으로 추출될 수도 있어 똑같은 표본이 생성되지 않기 때문에 각각의 다른 표본의 통계량을 구할 수 있습니다.
'통계학 이야기' 카테고리의 다른 글
| 67. R을 이용한 모평균에 대한 통계적 추론 (1) | 2024.06.08 |
|---|---|
| 66. 모평균에 대한 통계적 추론 III (1) | 2024.06.07 |
| 64. 모평균에 대한 통계적 추론 I (1) | 2024.01.16 |
| 63. 가설 검정(Hypothesis Testing) (0) | 2024.01.04 |
| 62. 추정(Estimation) - 구간 추정(Interval Estimation) (1) | 2023.12.28 |



