
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 산점도
- 반복있음
- html
- 가설검정
- 데이터 과학
- 변동분해
- version 2
- 이원배치 분산분석
- 고정효과모형
- JavaScript
- 확률
- 정규분포
- 오블완
- 통계학
- 글쓰기
- 분산분석
- r
- 경제학
- 변량효과모형
- 이항분포
- 에세이
- 반복없음
- 해운업
- version 1
- 티스토리챌린지
- 인공지능
- 회귀분석
- 추정
- 혼합효과모형
- css
- Today
- Total
생각 작업실 The atelier of thinking
17. R을 이용한 수치자료의 중심 구하기 본문
Chapter 17. R을 이용한 수치자료의 중심 구하기
R을 이용하여 평균, 중앙값, 최빈값 등 수치자료의 중심을 구해보겠습니다.
지난 15회차에 수치자료의 중심에 대해 알아봤습니다.
2023.09.05 - [통계학 이야기] - 15. 수치 자료의 중심 - 평균, 중앙값, 최빈값
15. 수치 자료의 중심 - 평균, 중앙값, 최빈값
일변량 자료 요약 (1) 수치형 - 평균, 중앙값, 최빈값, 분산, 표준편차, 범위, 분위수 등 (2) 범주형 - 도수분포표 (빈도수, 백분율) 다변량 자료 요약 (1) 수치형 - 공분산, 상관관계 (2) 범주형 - 분할
thinking-atelier.tistory.com
1. 자료 불러오기
◈ 대학 정보 공시 취업률 자료

위 자료는 통계학 관련 42개 학과의 취업률을 나타내고 있습니다.
14-2. R을 이용한 자료요약에 사용했던 자료입니다.
Job <- scan()
55.6 83.3 43.4 58.1 31.6 55.6 60.7 64.6 73.3 55.6 64.3
52.8 22.7 46.3 71.4 53.8 64.5 67.9 71.4 80.0 59.5 40.5
77.1 58.6 65.4 52.4 66.7 91.3 41.3 72.1 61.9 78.4 63.6
41.0 65.2 81.3 54.8 19.6 50.0 53.1 41.2 56.5
2. 산술평균
▶ mean ( ) 함수
수치형 데이터의 평균을 구하는 함수입니다.
mean(Job)
round(mean(Job),1)
위 mean( ) 함수는 아래의 식을 풀어주는 함수입니다.

따라서, R에서 함수가 아닌 수식을 이용해서 구할 수도 있습니다.
n <- length(Job)
sum(Job)/n
round(sum(Job)/n,1)
mean( ) 함수와 같은 값이 나오는 것을 확인할 수 있습니다.
3. 중앙값
▶ mean ( ) 함수
중앙값을 구하는 함수 입니다.
median(Job)
4. 절사평균
▶ mean ( x , trim = ) 함수
mean( ) 함수에서 trim이란 매개변수를 사용하여 절사평균을 구할 수 있습니다.
trim은 0에서 0.5 까지의 값을 가집니다.
mean(Job, trim=0.1)
mean(Job, trim=0)
mean(Job, trim=0.5)
trim = 0 일 때는 산술평균을 의미하고 trim=0.5 일 때는 중앙값을 의미합니다.
trim 은 계산에서 제외할 양 극단 값의 비율을 정합니다.
5. 최빈값
R에서 최빈값을 직접 구하는 함수는 없습니다.
최빈값은 빈도가 가장 많은 값입니다. 빈도를 구하는 table( ) 함수를 이용해서 구해보겠습니다.
table(Job)
max( ) 함수는 최대값을 구하는 함수입니다.
freq <- table(Job)
max(freq)
which( ) 함수는 조건을 만족하는 인덱스를 구하는 함수입니다.
freq <- table(Job)
maxfreq <- max(freq)
which(freq == maxfreq)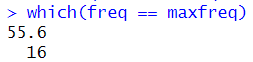
최빈값은 55.6 이고 인덱스는 16 임을 알려줍니다.
6. 가중평균
가중평균은 가중치를 더해 구한 평균값입니다.
▶ weighted.mean( )
mean( ) 함수에 가중치(weighted)를 더한 값으로 매개변수로 가중치가 추가됩니다.
앞서 평균의 한계에서 계산했던 가중평균을 R을 이용해 보겠습니다.


m <- c(0.62,0.63,0.37,0.33,0.28,0.06)
w <- c(933,585,918,792,584,714)
weighted.mean(m,w)
round(weighted.mean(m,w),2)
7. 기하평균
기하평균을 사용하는 가장 대표적인 예시로는 연평균 증가율을 구할 때 입니다.
예를 들어 전세계 해상물동량이 2002년에는 66억톤이 었는데 2021년은 119.82억톤이 되었습니다. 이 때, 연평균 증가율은 얼마일까요 ?
2002년과 2021년 사이의 증가율은 약 1.82 배 증가하였습니다. 연평균 증가율을 r 이라 했을 때, 이 값은 2002년 물동량 66억톤에 (1+r)을 2021년까지 계속 19번을 곱하면 119.82억톤이 되는 것입니다.
아래는 연평균 증가율(r)을 구하는 함수 입니다.
cagr <- function(s,e,n){
inc <- e/s
cagr <- inc^(1/n)-1
return(round(cagr,2))
}
cagr(6600,11982,19)0.03
결과값이 0.03 즉, 연평균 증가율은 3% 입니다.
정리
# 1. 자료불러오기
Job <- scan()
55.6 83.3 43.4 58.1 31.6 55.6 60.7 64.6 73.3 55.6 64.3
52.8 22.7 46.3 71.4 53.8 64.5 67.9 71.4 80.0 59.5 40.5
77.1 58.6 65.4 52.4 66.7 91.3 41.3 72.1 61.9 78.4 63.6
41.0 65.2 81.3 54.8 19.6 50.0 53.1 41.2 56.5
# 2. 산술평균
mean(Job)
round(mean(Job),1)
n <- length(Job)
sum(Job)/n
round(sum(Job)/n,1)
# 3. 중앙값
median(Job)
# 4. 절사평균
mean(Job, trim=0.1)
mean(Job, trim=0)
mean(Job, trim=0.5)
# 5. 최빈값
freq <- table(Job)
maxfreq <- max(freq)
which(freq == maxfreq)
# 6. 가증평균
m <- c(0.62,0.63,0.37,0.33,0.28,0.06)
w <- c(933,585,918,792,584,714)
weighted.mean(m,w)
round(weighted.mean(m,w),2)
# 7. 기하평균
cagr <- function(s,e,n){
inc <- e/s
cagr <- inc^(1/n)-1
return(round(cagr,2))
}
cagr(6600,11982,19)'통계학 이야기' 카테고리의 다른 글
| 19. R을 이용한 수치자료의 산포 구하기 (0) | 2023.09.11 |
|---|---|
| 18. 수치자료의 산포 - 분산, 표준편차,분위수 (0) | 2023.09.11 |
| 16. 수치 자료의 중심 - 평균의 한계 (0) | 2023.09.06 |
| 15. 수치 자료의 중심 - 평균, 중앙값, 최빈값 (0) | 2023.09.05 |
| 14-2. R 을 이용한 자료 요약 (0) | 2023.09.01 |



