
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 경제학
- version 2
- 인공지능
- 가설검정
- 티스토리챌린지
- 오블완
- r
- 변동분해
- 회귀분석
- 변량효과모형
- html
- 반복없음
- css
- 혼합효과모형
- 에세이
- 데이터 과학
- 추정
- 정규분포
- 글쓰기
- 통계학
- 반복있음
- 고정효과모형
- JavaScript
- version 1
- 이원배치 분산분석
- 해운업
- 분산분석
- 산점도
- 확률
- 이항분포
- Today
- Total
생각 작업실 The atelier of thinking
23. R을 이용하여 왜도, 첨도 구하기 본문
Chapter 23. R을 이용하여 왜도, 첨도 구하기
지난 회차에서 자료 분포의 형태를 나타내는 측도인 왜도와 첨도에 대해서 알아봤습니다.
2023.09.18 - [통계학 이야기] - 22. 수치자료의 형태 - 왜도, 첨도
22. 수치자료의 형태 - 왜도, 첨도
Chapter 22. 수치자료의 형태 - 왜도, 첨도 1. 분포의 형태 많은 통계분석 방법은 모집단이 중심위치를 기준으로 대칭(symmetric)이라고 가정합니다. 즉 자료의 분포형태가 정규분포를 따른다고 가정합
thinking-atelier.tistory.com
R을 이용해서 왜도와 첨도를 구해보겠습니다.
1. 자료 불러오기
자료는 17. R을 이용한 수치자료의 중심에서 사용했던 취업률 자료를 사용하겠습니다.
◈ 대학 정보 공시 : 취업률 자료

Job <- scan()
55.6 83.3 43.4 58.1 31.6 55.6 60.7 64.6 73.3 55.6 64.3
52.8 22.7 46.3 71.4 53.8 64.5 67.9 71.4 80.0 59.5 40.5
77.1 58.6 65.4 52.4 66.7 91.3 41.3 72.1 61.9 78.4 63.6
41.0 65.2 81.3 54.8 19.6 50.0 53.1 41.2 56.5
2. 표준화 및 히스토그램
R에서 왜도와 첨도를 직접 구하는 함수는 따로 없습니다. 그래서 왜도와 첨도를 구하는 함수를 R을 통하여 만들고자 합니다.
아래는 피어슨 왜도의 수식입니다.
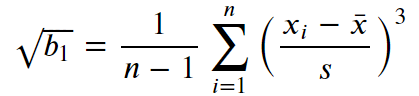
여기서,
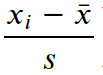
표준화를 하는 수식입니다. 따라서, 위 자료의 표준화를 먼저 진행합니다.
xbar <- mean(Job)
s <- sd(Job)
z <-(Job-xbar)/s
z
위 Job 의 자료를 표준화한 결과물을 z 에 담았습니다.
이 z 에 대한 히스토그램을 그려보겠습니다.
hist(z,breaks = c(-3,-2,-1,0,1,2,3),freq = FALSE, col="skyblue")
표준화를 한 z 의 평균은 0이며, 표준편차는 1 입니다. 위 히스토그램를 보면 평균 0 을 기준으로 완벽하지는 않지만 어느정도의 대칭인 듯 보이긴 합니다.
이제 위 히스토그램을 수치 측도인 왜도와 첨도를 구해보겠습니다.
3. 왜도 (Skewness)
위 왜도를 구하는 수식을 R 로 표현하면,
n <-length(Job) # 자료의 수
skewness <- sum(z^3)/(n-1)
skewness-0.3955213음의 왜도를 가진 것을 확인할 수 있습니다.
하지만, 보편적인 관점의 정규성 검정 기준은 절대값 3 미만 입니다. 이 기준으로 보면 위 자료는 정규분포를 이룬다고 가정할 수 있습니다.
▶ sum( ) 은 합계를 구하는 함수입니다.
4. 첨도 (Kurtosis)
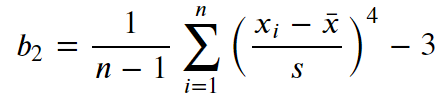
위 첨도의 수식을 R로 표현하면,
kurtosis <- sum(z^4)/(n-1)-3
kurtosis0.1065224나온 결과를 보면, 위 자료 분포에서 이상치가 있을 확률은 높지 않다고 판단할 수 있습니다.
5. 왜도와 첨도를 구하는 함수
위 코드들을 정리하여 왜도와 첨도를 구하는 함수를 만들어 보겠습니다.
g_shape <- function(x)
{
n <- length(z)
result <- c(NA,NA)
if (n >= 2)
{
z <- (x-mean(x))/sd(x)
skew <- sum(z^3)/(n-1)
kurt <- sum(z^4)/(n-1)-3
result <- c(skew,kurt)
}
return(result)
}g_shape(Job)-0.3955213 0.1065224자료의 수는 최소 2개는 있어야 하므로 조건문을 설정하였습니다.
'통계학 이야기' 카테고리의 다른 글
| 25. R을 이용한 범주형 자료 요약 (2) | 2023.09.21 |
|---|---|
| 24. 범주형 자료 요약 (0) | 2023.09.21 |
| 22. 수치자료의 형태 - 왜도, 첨도 (0) | 2023.09.18 |
| 21. R을 이용한 표준화 - 표준점수 구하기 (0) | 2023.09.15 |
| 20. 수치자료의 형태 - 정규분포 (0) | 2023.09.13 |



