
생각 작업실 The atelier of thinking
34. 조건부 확률 - 베이즈 정리의 활용 본문
Chapter 34. 조건부 확률 - 베이즈 정리의 활용
1. 사전확률 & 사후확률
베이즈 정리는 두 확률 변수의 사전확률과 사후확률 사이의 관계를 나타내는 정리이기도 합니다.
즉, 원인과 결과 형태의 문제에서 결과에 대한 원인 분석이 가능하게 하는 이론입니다.

(1) 사전확률 (Prior Probability)
P(B|A) 는 순서적으로 볼 때, 대부분 사건 A가 먼저 발생하고 B가 이어 발생하는 상황에 대한 확률을 말한다.
A는 원인 B는 결과라고 볼 수 있습니다. 이렇게 원인에서 결과를 도출해내는 것을 전향적 연구(prospective study)라고 합니다. 코호트 연구(Cohort Study)가 대표적인 예라 할 수 있습니다.여기서 원인인 사건 A의 가능성을 P(A) 또는 P(A)의 여사건은 결과인 사건 B가 관측되기 이전의 확률입니다. 그런 의미로 사전확률(prior probability)라고 말합니다.
즉, 사전확률은 특정 사상이 일어나기 전의 확률을 뜻합니다. 혹은 경계 확률, 선험적 확률은 베이즈 추론에서 관측자가 관측을 하기 전에 가지고 있는 확률분포를 의미합니다.
(2) 사후확률(Posterior Probability)
어떤 문제는 결과를 얻은 상태에서 그 결과가 발생하게 된 원인을 역으로 추정하기도 합니다. 결과에서 원인을 찾아내는 것입니다. 이러한 것을 후향적 연구(retrospectiv study)라 하며 사례-대조연구(case-control study)가 대표적인 예라 할 수 있습니다.
결과인 사건 B가 관측되었을 때 그 원인이 사건 A일 확률은 어떻게 구할 수 있을까요?조건부 확률 P(A| B) 로 구할 수 있습니다. 이 때 사건 B가 관측된 후의 A의 확률을 사후확률(posterior probability) 이라고 합니다.
◈ 예제 : 암진단
암 간이진단 검사를 실시하였다.간이진단 검사에서 암에 걸렸을 때 양성반응이 나올 확률은 0.96,
암에 걸리지 않았을 때 양성반응이 나올 확률이 0.05 로 알려져 있다.
만약 간이진단검사에서 양성반응이 나왔다면, 암에 걸렸을 확률은 ?
이 확률은 베이즈 정리를 사용하여 구할 수 있습니다. 다만, 문제를 수식화하는 것은 좀 까다롭다고 느껴집니다. 위 문제에서 암에 걸린 사건을 A 라 하고, 양성반응이 나온 사건을 B 라고 하겠습니다.
그렇다면 암에 걸렸을 때 양성반응이 나올 확률과 암에 걸리지 않았을 때 양성반응이 나올 확률은 아래와 같이 표현할 수 있습니다.

질문인 양성반응이 나왔을 때 암에 걸렸을 확률은 P(A| B) 로 나타낼 수 있습니다. 이것은 베이즈 정리를 사용하여 얻을 수 있습니다.

위 식에서 더 알아야 할 부분은 P(A) 입니다. 즉, 암에 걸릴 확률입니다. 이 때 암에 걸릴 확률은 사전확률이라 할 수 있습니다. 여기서는 0.001 이라고 가정하겠습니다.

계산 결과 약 1.9%의 확률이 나옵니다. 즉 양성반응이 나왔을 때 암에 걸렸을 확률은 1.9%인 것입니다.
이 수치는 기존 암에 걸릴 확률(사전확률)인 0.001보다는 19배 높은 수치이지만, 암에 걸렸을 때 양성반응이 나올 확률은 0.96이라는 수치를 보고서 예상했을 암에 걸릴 확률을 생각했던 것과 비교해 보면 현저히 낮은 수준이라 할 수 있습니다.
2. 확률수형도, 기대돗수나무
확률수형도 또는 기대돗수나무는 통계학에서 사용되는 도표 중 하나로, 주로 범주형 데이터의 분포를 시각적으로 표현하는 데 사용됩니다.
위 암진단 예제를 아래와 같이 시각화하여 표현할 수 있습니다.
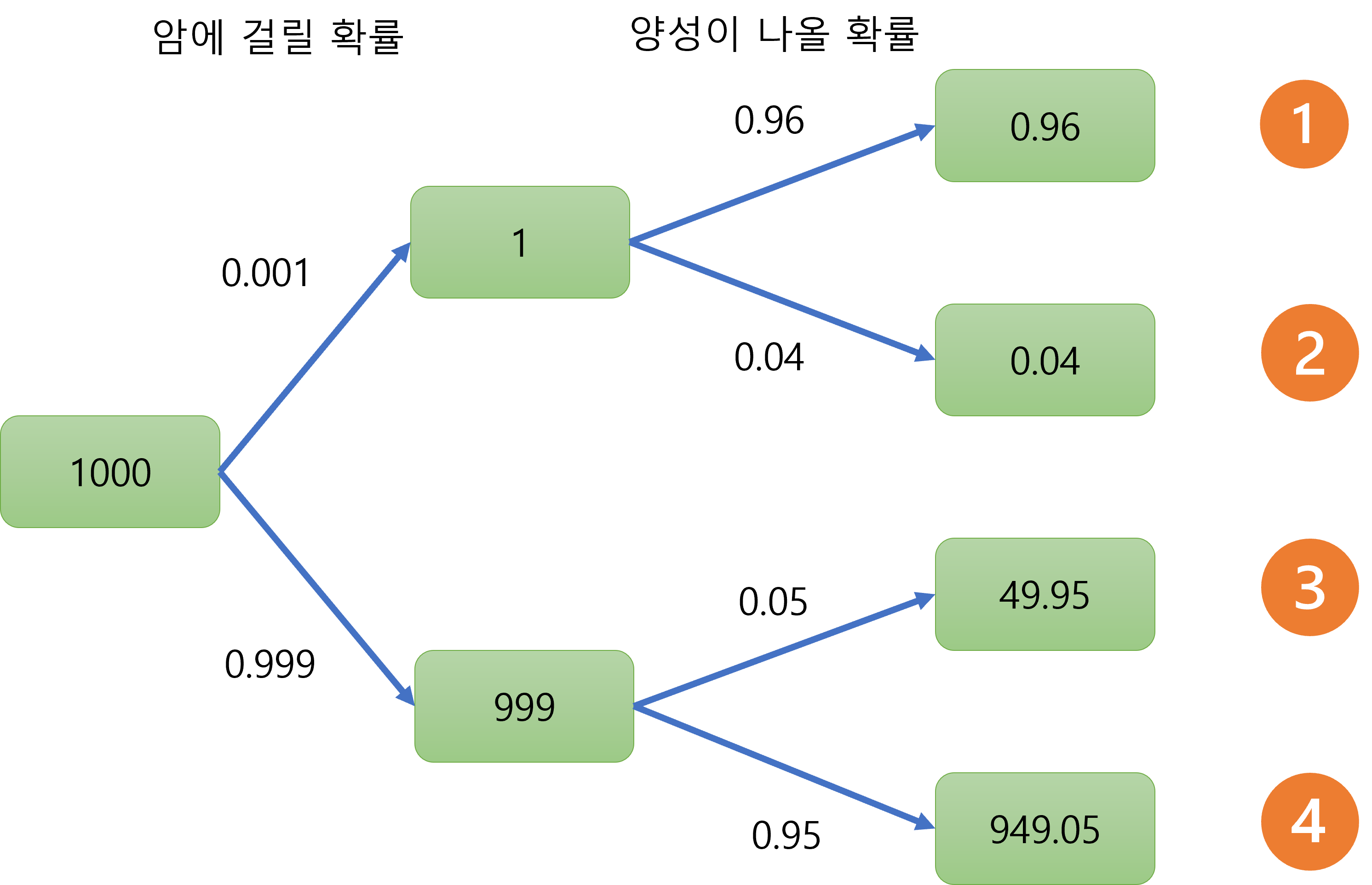
위 그림은 1000명의 사람을 검사했을 때 확률수형도 입니다.
양성반응이 나왔을 때 암에 걸렸을 확률을 구하려면, 양성반응이 나온 사람들 중 실제 암이 걸린 사람의 수의 비율을 구하면 됩니다. 즉 양성반응이 나온 경우는 1과 3 입니다. 그리고 이 중 암이 걸린 경우는 1 입니다.
확률은 1 / ( 1+3 ) 로 구할 수 있습니다. 즉, 0.96/(0.96+49.95) = 0.01886이 나옵니다.
3. 베이즈 정리 활용 예제
베이즈 정리는 원인과 결과간의 관계를 추론하는 데 사용되며, 머신러닝의 여러 분야에서 특히 확률적 모델링, 판정, 예측에 중요한 역할을 합니다.
◈ 스팸메일 필터
어떤 메일시스템의 수신메일 중 40%가 스팸메일(S)이고 나머지는 정상메일(N)이라고 한다.
스팸메일 중 25%는 "A" 라는 단어를 포함하고 정상메일 중 2%가 이 단어를 포함하고 있다.
수신메일 내용 중에 "A"라는 단어가 있을 때 이 메일이 스팸메일일 확률은 ?
위 문제를 수식화 하면,
스펨메일을 S, 정상메일을 N 이라 할 때, P(S) = 0.4 , P(N) = 0.6 로 표현할 수 있습니다. 이는 사전확률입니다.
A 라는 단어가 있을 때를 사건 A 라 하면, 스펨메일 중 25%는 A를 포함하는 것은, P(A|S) = 0.25
정상메일 중 2%는 A를 포함하는 것은, P(A|N) = 0.02 로 표현할 수 있습니다.
질문인 A 라는 단어가 있을 때 이 메일이 스팸메일일 확률은 P(S|A) = ? 로 표현할 수 있습니다.

위 식에서 P(A)를 구하려면, S 안에 있는 A와 N 안에 있는 A를 더해야 합니다.

아래의 베이즈 정리를 이용해서


위 식에 각각을 대입하여 계산하면, P(A) = 0.4X0.025 + 0.6X0.02 = 0.112 입니다.
이 식에 각각의 값을 대입하면
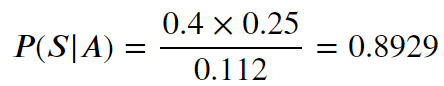
A 라는 단어가 포함되어 있을 때, 스팸메일일 확률은 89.29%에 이릅니다.
이러한 스펨메일 분류는 머신러닝에서 베이즈 정리를 기반으로 한 나이브 베이즈 분류기(Naives Bayes Classifier)와 같은 알고리즘을 사용하여 실제 많은 회사에서 사용하고 있습니다.
'통계학 이야기' 카테고리의 다른 글
| 36. 확률함수 - 확률질량함수 & 확률밀도함수 (1) | 2023.10.17 |
|---|---|
| 35. 확률변수와 확률분포 (0) | 2023.10.16 |
| 33. 조건부 확률 - 베이즈 정리(Bayes' theorem) (1) | 2023.10.12 |
| 32. 고전적 확률 vs. 조건부 확률 (1) | 2023.10.11 |
| 31. R을 이용한 경우의 수 구하기 (1) | 2023.10.09 |



