
생각 작업실 The atelier of thinking
35. 확률변수와 확률분포 본문
Chapter 35. 확률변수와 확률분포
1. 도대체 확률이란 무엇인가?
확률이란 말은 여러 측면에서 다양하게 사용됩니다. 통계학에서의 확률은 어떤 사건(event)이 일어날 가능성을 수학적으로 측정한 것을 말합니다.
(1) 고전적 확률(Classical Probability)
통계에서 언급하는 확률은 대부분 고전적 확률을 의미합니다.
주사위 던지기와 동전 던지기와 같이 모든 결과가 나올 확률이 동일하다는 전제하에 특정 사건이 나올 확률을 계산합니다.
(2) 나열 확률(Enumerative Probability)
모든 가능한 경우를 생각하고 그 중 내가 관심이 있는 사건이 일어나는 비율을 생각합니다.
예를 들면 검은색 공 3개와 빨간색 공 2개가 들어 있는 상자에서 공을 하나 꺼낼 때 빨간 공이 나올 확률은 2/5 입니다.
(3) 장기 빈도 확률(Long-run Frequency Probability)
동일한 사건이 반복적으로 일어날 때 발생하는 비율을 의미합니다.
하지만 모든 사건이 반복적으로 일어나지는 않습니다.
(4) 성향(Propensity)
특정 사건이 일어날 진짜 가능성을 의미합니다.
하지만 본인이 전지전능하지 않은 경우 이 "성향"을 알아내는 것은 (거의) 불가능합니다.
(5) 주관적 확률(Subjective Probability)
내가 월드컵에서 한국이 4강까지 진출할 경우 10만원을 주는 도박에 만 원을 걸었다고 하면, 이 경우 나의 주관적 확률은 0.1이 됩니다.
이처럼 확률이라는 말은 다양한 의미로 쓰입니다. 통계적 확률은 다음과 같은 상황을 설명할 때 필요합니다.
데이터가 컴퓨터(혹은 난수표)에 의해서 임의로 생성된다고 할 때
이미 존재하는 데이터를 임의로 선택하고자 할 때
임의성은 없지만 마치 데이터를 임의로 생성되었다고 가정할 때
등 수학적 측정이 필요할 때 필요합니다.
따라서, 통계학에서의 확률의 가장 핵심은 수학적으로 표현가능해야 한다는 것입니다.
확률을 수학적으로 표현하기 위해 필요한 것이 확률변수와 확률분포라고 할 수 있습니다.
2. 확률변수 (Random Variable)
확률변수를 영어로 표현하면 Random Variable인데, 여기서 Random은 무작위라는 의미입니다.
확률변수를 수학적으로 정의하면 표본공간에서 정의된 실함수(real-valued function : 실수의 어떤 집합의 각 원소에 하나의 실수를 대응시키는 함수)를 말합니다.
확률변수는 정의역(출력값을 도출하는 입력 값의 집합)이 표본공간이고 공역(함수의 값들이 속하는 집합)이 실수인 함수입니다.
또한, 표본공간은 확률실험에서 나왔고, 나온 원소들을 숫자로 바꿔 주는 것이 확률변수입니다.
▶ 확률실험의 2 가지 특징
(1) 실험시작전에 모든 결과를 알 수 있습니다. (표본공간)
(2) 불확실성(사건)- 어떠한 사건이 얼마나 일어날 지는 알 수가 없습니다.
통계학에서는 불확실성을 가지는 사회적,자연적 현상을 일종의 확률실험으로 이해하고, 표본공간을 숫자로 표시하고 불확실한 현상을 수학적으로 모형화하여 구체적으로 계량화된 분석하는 학문이라고 할 수 있습니다.
통계학은 불확실성을 제거하는 것이 아니라 불확실성을 수학적으로 모델링하는 것입니다. 이 모델링의 첫단계가 숫자로 바꿔주는 함수, 확률변수인 것입니다.
예를들어, 동전던지기를 한다고 할 때, 앞면이 나오면 1이라 기록하고 뒷면이 나오면 0 이라 기록하는 규칙을 만들 수 있습니다. 이처럼 특정 결과를 숫자와 연관시키는 규칙을 확률변수라고 합니다.
이 때 구체적으로 특정사건(동전던지기)을 생각하고 특정 사건의 가능한 모든 결과물(앞면,뒷면)의 집합을 표본공간(sample space)라고 할 수 있습니다. 확률변수는 이러한 표본공간에 속한 각각의 원소에 특정 숫자를 대입한 값이라 생각하면 됩니다. 즉, 앞면이 나오면 1, 뒷면이 나오면 0 이란 규칙으로 표현할 수 있습니다.
또한 수학적 모형을 통해서 구체적으로 또는 계량화된 분석을 할 수 있게됩니다.
즉, 불확실한 현상을 수학적인 모형으로 만들 수 있는 근거를 마련하려는 이유로 확률변수를 사용하는 것입니다.
◈ 예제 : 동전 3개 던지기
동전을 3개 던지는 확률실험을 했을 때, 표본공간은 미리 알 수 있습니다.
앞면을 H(head), 뒷면을 T(tail) 로 표현하면 표본공간은 아래와 같이 표현할 수 있습니다.

표본공간은 총 8개의 원소를 가지고 있습니다.
여기서 관심이 있는 사건은 동전이 앞면 나온 횟수라고 할 때, 이를 확률변수 X라 하고 이를 구하면,

관심있는 사건이 동전 앞면과 뒷면의 차리라고 하고, 이를 확률변수 Y라하고 이를 구하면,

이렇게 표본공간의 원소를 숫자로 바꿔주는 것이 확률변수 입니다.
확률변수는 표본공간에 있는 원소의 형태에 따라 확률변수의 형태가 다르게 나올 수 있습니다.
표본공간의 원소가 셀 수 있는 수치자료 즉, 이산자료라면 확률변수도 셀 수 있게 나오고, 연속적인 실수형태라면 확률변수도 실수 형태로 나타납니다.
▶ 확률변수의 형태
(1) 이산확률변수 (discrete random variable)
(2) 연속확률변수 (continuous random variable)
3. 확률분포(Probability Distribution)
확률분포는 확률변수가 특정 값을 가질 확률을 나타내는 것입니다.
확률변수는 표본공간의 값을 숫자로 바꾼 함수이고, 확률변수가 어떤 값을 가진다는 것은 표본공간 내에 대응하는 원소들이 존재한다는 것입니다. 확률변수가 숫자로 표시되면 해당 숫자에 대한 확률을 구할 수 있습니다.
◈ 예제 : 동전 3개 던지기
앞서 동전을 3개 던지는 확률실험을 할 때, 표본공간은 총 8개 였습니다.
앞면의 수를 나타내는 확률변수 X의 값은 0,1,2,3 으로 나타났습니다.
확률변수 X, 0,1,2,3 에 대한 각각의 확률은 아래와 같이 나타낼 수 있습니다.
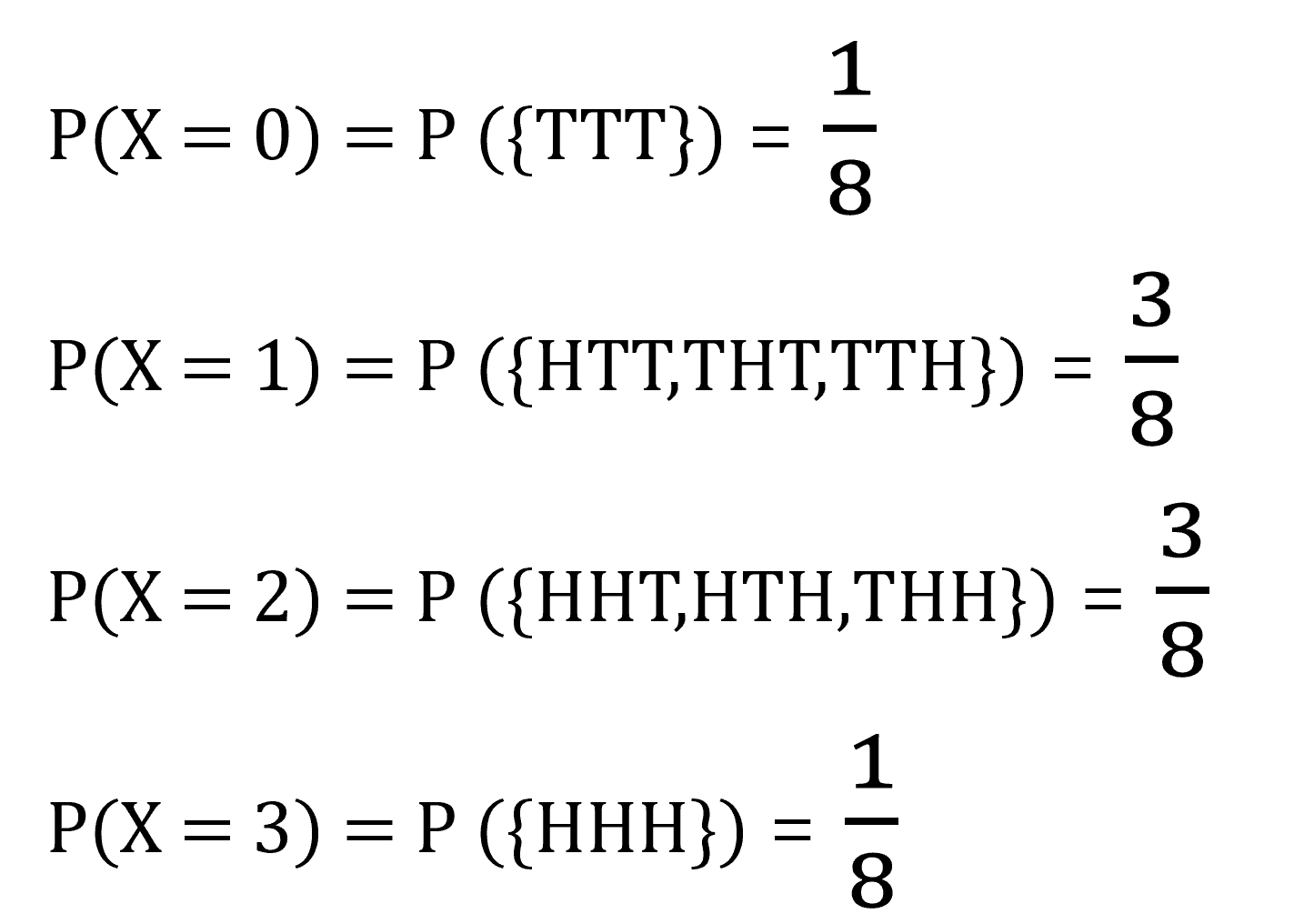
확률변수의 값에 따라 확률이 어떤 형태로 분포되어 있다는 말을 할 수 있습니다.
이는 그림으로도 표시 가능합니다.
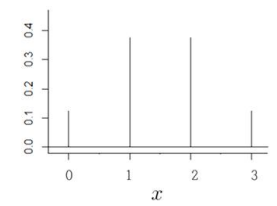
확률분포는 확률변수의 값에 대해 확률을 표시한 것입니다.
이를 표로 나타내면,

※ 보통 변수는 X,Y,Z 등 알파벳 대문자를 사용하고, 관측값은 x,y,z 등 알파벳 소문자를 사용하여 구분합니다.
이처럼 확률은 모집단이 어떤 형태로 이루어져 있는지를 보여줍니다.
확률분포는 모집단을 숫자로 표시했을 때의 형태입니다. 즉, 확률분포는 표본의 구조가 아니라 모집단의 확률구조입니다.
4. 확률변수와 확률분포의 관계
확률변수는 특정한 값을 취할 확률을 나타내는 변수로, 확률분포는 확률변수가 가질 수 있는 모든 값과 그 값이 나타날 확률을 나타내는 함수입니다.
확률분포는 확률변수의 특성을 설명하는 도구로 사용됩니다. 특정 확률변수가 어떤 분포를 다른다면, 그 확률변수에 대한 확률분포를 통해 해당 확률변수의 특성을 이해하고 확률을 계산할 수 있습니다. 따라서, 확률분포를 알면 확률변수의 특성과 그 값들의 확률을 이해할 수 있습니다.
확률변수의 모든값 → 확률분포 → 확률변수의 확률구조 → 모집단의 형태
확률분포는 일반적으로 모집단의 특성을 추상화한 것으로 볼 수 있습니다. 모집단의 모든 개체가 가지는 특성을 정확히 파악하기는 어려우므로, 확률분포를 통해 모집단의 특성을 확률적으로 모델링합니다. 확률분포를 통해 모집단의 특성을 일정한 수학적 형태로 표현하고, 이를 기반으로 확률적인 추론이나 예측을 수행할 수 있습니다.
확률분포는 모집단의 특성을 확률적으로 표현하고, 이를 기반으로 통계적인 분석을 할 수 있게 돕습니다. 모집단의 특성을 모르는 상황에서 확률분포를 추정하여 통계적 추론을 수행하는 것이 통계학의 일반적인 접근 방법 중 하나입니다.
'통계학 이야기' 카테고리의 다른 글
| 37. 확률변수의 기대값(Expected Value) (1) | 2023.10.18 |
|---|---|
| 36. 확률함수 - 확률질량함수 & 확률밀도함수 (1) | 2023.10.17 |
| 34. 조건부 확률 - 베이즈 정리의 활용 (0) | 2023.10.13 |
| 33. 조건부 확률 - 베이즈 정리(Bayes' theorem) (1) | 2023.10.12 |
| 32. 고전적 확률 vs. 조건부 확률 (1) | 2023.10.11 |



