
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- version 1
- 회귀분석
- 분산분석
- 에세이
- 해운업
- 글쓰기
- 가설검정
- version 2
- html
- css
- 확률
- 정규분포
- 혼합효과모형
- 변량효과모형
- 경제학
- 반복없음
- 산점도
- 고정효과모형
- 이항분포
- 반복있음
- JavaScript
- 통계학
- 인공지능
- r
- 데이터 과학
- 추정
- 티스토리챌린지
- 변동분해
- 오블완
- 이원배치 분산분석
- Today
- Total
생각 작업실 The atelier of thinking
37. 확률변수의 기대값(Expected Value) 본문
Chapter 37. 확률변수의 기대값(Expected Value)
확률변수의 통계량은 확률분포를 표현하기 위한 값들이며, 이 값들은 확률함수를 통해 계산할 수 있습니다.
1. 기대값(Expected Value)
확률변수의 기대값은 해당 확률변수가 가질 수 있는 각 값에 대해 그 값들의 가중 평균을 계산한 것이라 말할 수 있습니다. 기대값은 확률변수의 "평균적인" 값으로 생각할 수 있습니다.
확률변수에 대해 평균적으로 기대하는 값 = 모평균(population mean) = 확률분포(또는 모집단)의 무게중심
하나의 확률과정에 의해 결정되는 숫자는 하나의 값 주위로 분포합니다.
이 때 기대값(Expected Value)은 분포의 무게중심에 해당되는 값입니다. 즉 확률변수의 기대값은 확률분포의 중심위치를 말합니다.
(1) 표본평균에서 기대값 유도
확률변수 각 값은 각각의 자료라고 할 수 있습니다. 확률변수의 기대값은 표본평균을 구하는 방식에서 유도해올 수 있습니다.
우선, 표본평균의 일반식은 아래와 같습니다.
ˉx=x1+x2+⋯+xnn=1nn∑i=1xi
◈ 예제 : { 1, 2, 3, 4, 5, 6}으로 이루어진 모집단으로부터 5개의 표본을 무작위로 선택해서 얻은 값이 1,1,2,5,6 이라 할 때,
표본평균을 계산하면, 아래와 같이 할 수 있습니다.
ˉx=1+1+2+5+65=3
위 계산산식을 각 관측된 값에 그 값이 차지하는 비율을 곱하여 더한 것으로 표시할수 있습니다.
ˉx=1×25+2×15+3×05+4×05+5×15+6×15=3
이를 일반식으로 표현하면,
표본크기 : n,xi=i 라 했을 때, ni 값이 i 표본의 수
ˉx=x1×n1n+x2×n2n+x3×n3n+x4×n4n+x5×n5n+x6×n6n
간략히는
ˉx=6∑i=1xinin
여기서 각 표본의 비율을 p라 한다면, pi=nin 라 할 수 있습니다.
따라서, 위 식은 아래와 같이 표현할 수 있습니다.
ˉx=6∑i=1xipi
(2) 기대값의 일반식
표본크기 n 이 계속 커진다면, 표본은 모집단에 이르고, 표본평균은 모평균이 되고 결국 각 표본의 비율 pi 는 확률함수 $ f(x_i) 가 됩니다. 이를 식으로 표현하면,
ˉx=∑i=1xipi=∑i=1xif(xi)=E(X)=μ
기대값은 E(X) 혹은 μ(뮤)로 표기합니다.
기대값을 구하는 방법은 이산확률변수인지 연속확률변수인지에 따라 다르게 계산합니다.
이산확률변수는 확률질량함수를 연속확률변수는 확률밀도함수를 각각 사용하여 계산합니다.
각각의 계산식은 아래와 같습니다.
▶ 이산확률변수 X 의 기대값
E(X)=∑xxf(xi)=μ
▶ 연속확률변수 X 의 기대값
E(X)=∫xxf(x)dx=μ
2. 확률변수의 변환(Transfromation)
확률변수의 변환이란 어떤 함수를 통해서 또 다른 확률함수를 만드는 것입니다. 이미 만들어진 확률변수 그 자체보다는 변환을 해서 사용해야하는 경우가 있습니다.
변환된 확률변수도 여전히 확률변수이기 때문에 기존의 확률변수의 성질을 그대로 가지고 있습니다.
또한 변환된 확률변수의 확률분포도 존재하게 됩니다.
◈ 예제 : 확률변수 X의 변환
확률변수 X가 아래와 같은 확률분포를 가지고 있을 때,
| x | -1 | 0 | 1 | 2 |
| P(X=x) | 0.1 | 0.3 | 0.2 | 0.4 |
확률변수 X에 제곱을 하여 변환한 확률변수를 W 라고 했을 때,
W=X2
로 나타낼 수 있습니다. 이 때 W의 확률분포를 구하려면, 기존의 확률변수 값과 연결하면 됩니다.
| x | -1 | 0 | 1 | 2 |
| P(X=x) | 0.1 | 0.3 | 0.2 | 0.4 |
| w | 1 | 0 | 1 | 4 |
P(W=0) = 0.3 , P(W=1) = 0.1+0.2 = 0.3 , P(W=4) = 0.4
변환된 확률함수 W의 기대값을 구하면,
E(W)=0×0.3+1×0.3+4×0.4=1.9
이 식을 X의 관점에서는 아래와 같이 표현할 수 있습니다.
E(X2)=02×0.3+(−12×0.1+12×0.2)+22×0.4=1.9
이것을 일반식으로 표현하면,
E(W)=2∑x=−1x2f=E(X2)
즉, 변환전 x의 값인 -1,0,1,2 를 넣으면 변형된 제곱의 값인 0,1,4 의 확률에 대한 기대값으로 나오는 것입니다.
확률변수 X 변환함수를 Y 라 하면, Y = g(X) 로 표현할 수 있습니다.
이 변환된 함수 Y의 기대값은 아래와 같습니다.
▶ 이산확률변수 X 의 변환된 함수 Y 기대값
E(Y)=E(g(X))=∑xg(x)fX(x)
▶ 연속확률변수 X 의 변환된 함수 Y 기대값
E(Y)=E(g(X))=∫xg(x)fX(x)
3. 기대값의 성질
확률변수의 기대값은 확률변수가 가질 수 있는 값들의 평균적인 값으로, 확률분포의 중심을 나타냅니다.
확률변수의 기대값에 대한 주요 성질은 다음과 같습니다.
(1) 상수의 기대값은 상수 자체이다.
임의의 상수 a의 기대값은 아래와 같이 구할 수 있습니다.
E(a)=∑xaf(x)
이 때 상수 a는 x에 영향을 받지 않으므로 앞으로 빼낼 수 있습니다.
E(a)=a∑xf(x)
이전 회차에서 $ \sum_{x} f(x) =1 $ 임을 알고 있습니다. 따라서 이를 적용하면,
E(a)=a
상수의 기대값은 상수 자체임을 알 수 있습니다.
(2) 선형성
확률변수에 대한 선형변환(상수배 및 상수덧셈)을 적용한 확률변수의 기대값은 해당변환을 각각 적용한 기대값의 선형조합과 동일합니다.
확률변수 X를 aX+b로 변환했을 때의 기대값은 아래와 같이 구할 수 있습니다. (a,b는 상수)
E(aX+b)=∑(ax+b)f(x)
이를 각각 배분하여 표현하면,
E(aX+b)=∑axf(x)+∑bf(x)=a∑xf(x)+b
상수 a를 앞으로 빼고, ∑bf(x)=b임은 상수의 기대값에서 확인하였습니다.
∑xf(x)=E(X) 는 X의 기대값입니다. 따라서, 이를 간략히 정리하면, 아래와 같습니다.
E(aX+b)=aE(X)+b
결국 확률변수에 대한 선형변환은 각각 적용한 기대값의 선형조합과 동일합니다.
(3) 변환된 확률변수 합의 기대값
확률변수 X의 변환된 함수를 g1(X),g2(X) 라 할 때 두 함수 합의 기대값은 아래와 같습니다.
E(g1(X)+g2(X))=∑x(g1(x)+g2(x))f(x)
이를 각각 배분하여 표현하면,
E(g1(X)+g2(X))=∑g1(x)f(x)+∑g2(x)f(x)=E(g1(X))+E(g2(X))
변환된 두 함수의 합의 기대값은 각각의 함수의 기대값의 합과 같습니다.
◈ 예제 : 동전 3개 던지기
이전회차에서 사용했던 동전을 3개 던지는 확률실험을 할 때 앞면의 수를 나타내는 확률변수 X는 아래와 같이 나타납니다.
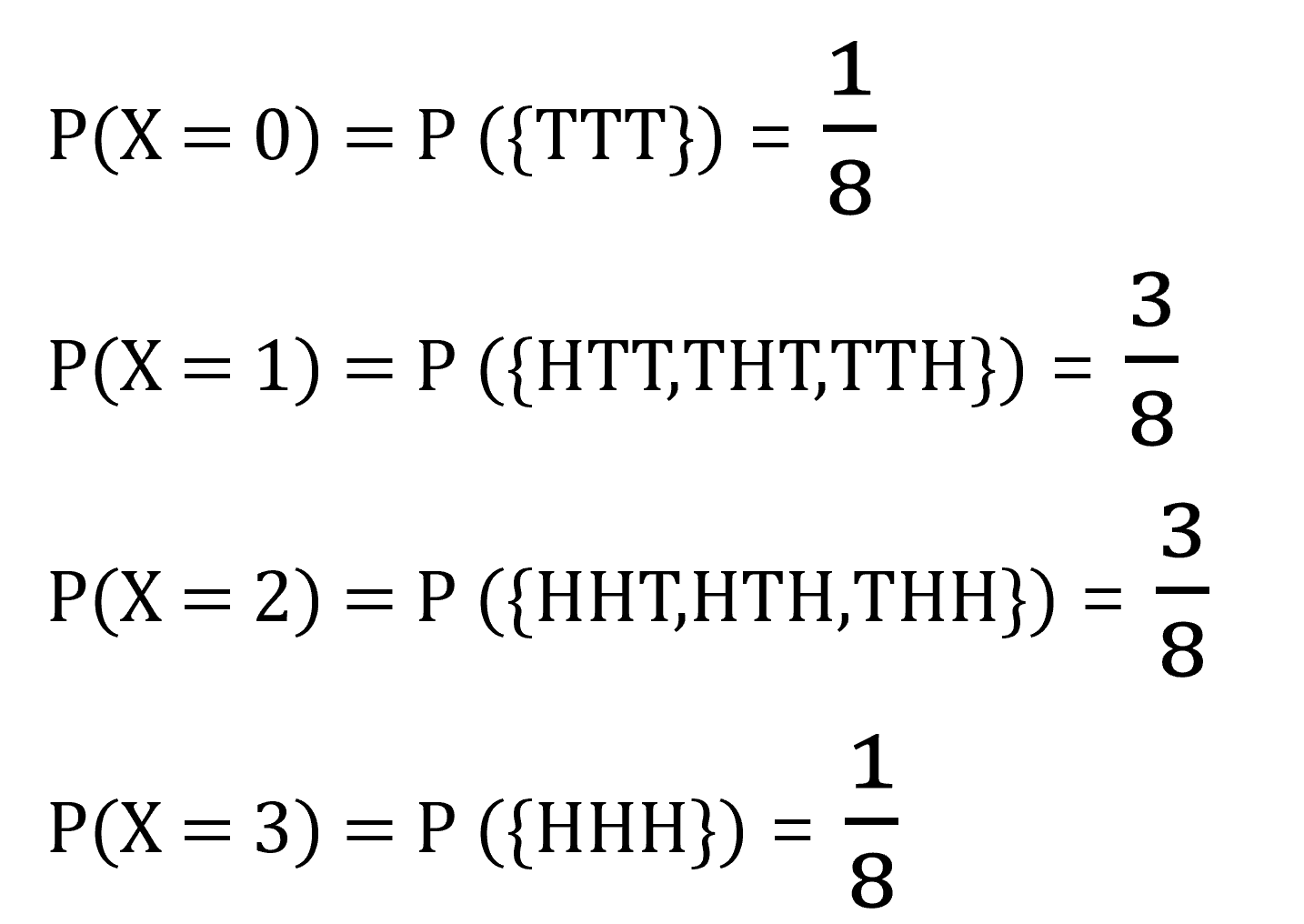
이를 확률질량함수로 표현하면, 아래와 같이 나타냈습니다.
f(0)=18,f(1)=38,f(2)=38,f(3)=18
(1) 확률변수 X에 대한 기대값은 ?
E(X)=3∑x=0xf(x)
=0×18+1×38+2×38+3×18=128=1.5
(2) 확률변수 X에 제곱한 값의 기대값은 ?
E(X2)=3∑x=0x2f(x)
=02×18+12×38+22×38+3×18=3
(3) 확률변수 X를 변환한 함수 (X−1.5)2 의 기대값은 ?
E((X−1.5)2)=3∑x=0(x−1.5)2fX(x)
위 식을 펼쳐보면,
=3∑x=0x2fX(x)−33∑x=0fX(x)+3∑x=01.52fX(x)
각 항은 아래와 같이 나타낼 수 있습니다.
=E(X2)−3E(X)+1.52=0.75
확률변수의 기대값은 확률분포의 특성을 나타내는 중요한 지표로서, 확률변수의 특성과 분포를 이해하는데 도움을 줍니다.
'통계학 이야기' 카테고리의 다른 글
| 39. 확률분포 - 결합분포&주변분포 (2) | 2023.10.20 |
|---|---|
| 38. 확률변수의 분산과 표준편차 (1) | 2023.10.19 |
| 36. 확률함수 - 확률질량함수 & 확률밀도함수 (1) | 2023.10.17 |
| 35. 확률변수와 확률분포 (0) | 2023.10.16 |
| 34. 조건부 확률 - 베이즈 정리의 활용 (0) | 2023.10.13 |



