
생각 작업실 The atelier of thinking
87. 분산분석 - 변동분해 본문
Chapter 87. 분산분석 - 변동분해
1. 변동분해(Decomposition of Variance)
분산분석(ANOVA)의 변동분해는 전체 변동을 다양한 요인 또는 처리로 분해하는 과정을 의미합니다. 이러한 변동분해를 통해 각 요인 또는 처리가 종속 변수에 미치는 영향을 평가하고 설명할 수 있습니다. 변동분해의 주요 목적과 사용 이유는 다음과 같습니다
(1) 요인 간 차이 비교
변동분해를 통해 각 요인이나 처리 간의 변동을 비교할 수 있습니다. 이를 통해 각 요인 또는 처리가 종속 변수에 미치는 영향의 정도를 파악할 수 있습니다.
(2) 요인의 중요성 확인
변동분해를 통해 각 요인이나 처리가 전체 변동 중에서 어느 정도의 비율을 차지하는지 확인할 수 있습니다. 이를 통해 각 요인 또는 처리의 상대적인 중요성을 평가할 수 있습니다.
(3) 분석 결과의 이해
변동분해를 통해 분석 결과를 더욱 명확하게 이해할 수 있습니다. 각 요인이나 처리의 변동을 수치화하여 제공하기 때문에 분석 결과를 쉽게 이해하고 해석할 수 있습니다.
(4) 통계적 결론 도출
변동분해를 통해 각 요인이나 처리의 통계적 유의성을 평가할 수 있습니다. 이를 통해 각 요인이나 처리가 종속 변수에 영향을 미치는지 여부를 판단하고 통계적 결론을 도출할 수 있습니다.
2. 일원 배치 분산분석의 변동분해
(1) 모형식
2024.06.28 - [통계학 이야기] - 85. 일원배치 분산분석(One-Way ANOVA)
85. 일원배치 분산분석(One-Way ANOVA)
Chapter 85. 일원배치 분산분석(One-Way ANOVA) 분산분석(ANOVA, Analysis of Variance)은 세 개 이상의 그룹 간의 평균차이를 비교 하는 통계적 기법입니다. 분산분석은 반응변수(종속변수)의 수에
thinking-atelier.tistory.com
앞서 일원배치 분산분석에서 언급했던 모형식은 아래와 같습니다.
$i = 1,2,...,p, \quad j = 1,2,...,n_i$ 일 때,
$$Y_{ij} = \mu_i + \epsilon_{ij}$$
$$ = \mu + (\mu_i-\mu)+\epsilon_{ij}$$
$$=\mu+\alpha_i+\epsilon_{ij}$$
이 때, 각 항은 아래와 같습니다.
$\mu$는 전체 모평균을 말합니다.
$\alpha_i$는 $i$번째 처리효과로 $\mu_i-\mu$ 로 나타내고, 모든 처리효과의 합은 0 입니다. $\sum \alpha_i = 0$
$\epsilon_{ij}$는 오차항을 말하며 관측값과 모델사이의 잔차를 말합니다.
위 모형식은 아래와 같이 추정량으로 표현할 수 있습니다.
$$Y_{ij} = \mu_i + \epsilon_{ij} = \mu+(\mu_i-\mu)+\epsilon_{ij}$$
위 식에서 $\bar{Y} \implies \mu$ 로, $\bar{Y_i} \implies \mu_i$로 대체할 수 있습니다.
따라서 오차항은,
$$\epsilon_{ij} = Y_{ij}-\mu_i \implies e_{ij} = Y_{ij}-\bar{Y_i}$$
로 나타낼 수 있습니다. 이 때 $e_{ij}$는 잔차(residuals)라고 합니다.
모형식을 위 추정량을 대입하고 정리하면 아래와 같이 표현할 수 있습니다.
$$Y_{ij} - \bar{Y} = \bar{Y_i} - \bar{Y} + Y_{ij} - \bar{Y_i} $$
(2) 직관적 개념
위 식의 각 항의 의미는 아래와 같습니다.
$Y_{ij}-\bar{Y} :$ 관측값이 전체평균에서 얼마나 떨어져 있는 정도 $\implies$ 변동
$\bar{Y_i}-\bar{Y} :$ 각 수준의 평균이 전체 평균에서 떨어져 있는 정도 $\implies$ 처리효과
$Y_{ij}-\bar{Y_i} :$ 관측값이 각 수준의 평균에서 떨어져 있는 정도 $\implies$ 잔차(오차)
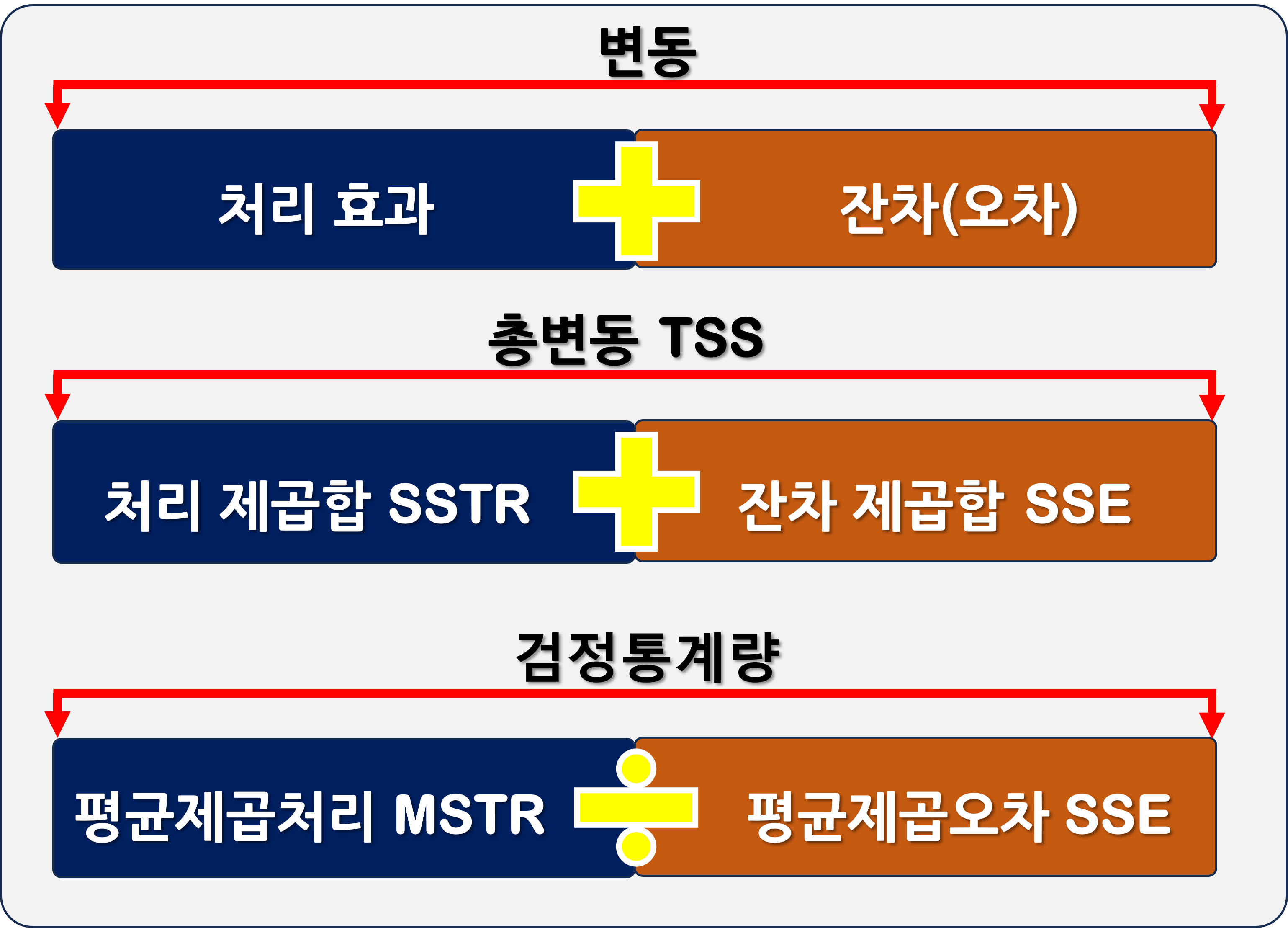
변동은 처리효과와 잔차의 합이라 할 수 있습니다.
변동 = 처리효과 + 잔차(오차)
(3) 제곱합(Sum of Square)
통계학에서 제곱합을 사용하는 경우가 종종 있는데, 변동분해에서 제곱합을 사용하는 이유는 각 처리나 요인의 효과를 비교할 때 양수 값으로 표현되어 편리합니다. 특히 분산의 경우 음수가 나온다면 해석의 어려움이 있기 때문입니다.
또한, 제곱합을 통해 변동이나 차이의 크기를 시각화하고 요인 간의 상대적인 중요성을 파악할 수 있습니다. 이를 통해 각 요인이 전체 변동에 얼마나 기여하는지를 이해할 수 있습니다.
위 식의 각 항에 제곱을 한 후 더해도 등식은 성립합니다.
$$Y_{ij} - \bar{Y} = \bar{Y_i} - \bar{Y} + Y_{ij} - \bar{Y_i} $$
$$\sum_{i=1}^p \sum_{j=1}^{n_i} (Y_{ij} - \bar{Y})^2 = \sum_{i=1}^p \sum_{j=1}^{n_i}(\bar{Y_i} - \bar{Y} + Y_{ij} - \bar{Y_i})^2 $$
$$= \sum_{i=1}^p \sum_{j=1}^{n_i} (Y_{ij} - \bar{Y_i})^2 + \sum_{i=1}^p (\bar{Y_i} - \bar{Y})^2 +2\sum_{i=1}^p \sum_{j=1}^{n_i}(\bar{Y_i} - \bar{Y})(Y_{ij}-\bar{Y_i}) $$
위 식에서 $\sum_{j=1}^{n_i}(Y_{ij}-\bar{Y_i})=0$ 이므로
$$2 \sum_{i=1}^p(\bar{Y_i}-\bar{Y}) \sum_{j=1}^{n_i}(Y_{ij}-\bar{Y_i}) = 0$$
이 됩니다. 따라서, 아래와 같이 정리할 수 있습니다.
$$\sum_{i=1}^p \sum_{j=1}^{n_i} (Y_{ij}-\bar{Y})^2 = \sum_{i=1}^p \sum_{j=1}^{n_i} (Y_{ij} - \bar{Y_i})^2 + \sum_{i=1}^p (\bar{Y_i} - \bar{Y})^2 $$
위 각 항은 아래와 같이 표현합니다.
$\sum \sum ( Y_{ij}-\bar{Y} )^2$ : 총변동 TSS , 자유도 N-1
$\sum \sum (Y_{ij}-\bar{Y_i})^2$ : 잔차(오차) 제곱합 SSE, 자유도 N-p
$\sum \sum (\bar{Y_i}-\bar{Y})^2$ : 처리제곱합 SSTR, 자유도 p-1

TSS : Total Sum of Square
SSE : Sum of Square Error
SSTR : Sum of Square due to TReatment
(4) 평균 제곱(Mean Square)
평균제곱은 제곱합(sum of squares)을 해당 제곱의 자유도(degrees of freedom)로 나눈 값입니다.
▶ 평균 제곱 처리 ( Mean Square due to TReatment )
효과에 대한 평균제곱 (Mean Square for Effects) 으로 각 처리나 요인이 설명하는 변동을 의미합니다. 예를 들어, 그룹 간의 차이를 나타내는 그룹 효과, 처리 간의 차이를 나타내는 처리 효과 등이 있습니다.
$$MSTR = \frac{SSTR}{p-1}$$
▶ 평균 제곱 오차 ( Mean Square Error )
오차에 대한 평균제곱 (Mean Square for Error)으로 모형에서 설명하지 못하는 변동을 의미합니다. 오차에 대한 평균제곱은 주로 통계적 가설 검정에서 사용되며, 모형이 설명하지 못하는 잔차에 대한 분산을 나타냅니다.
$$MSE = \frac{SSE}{N-p}$$
평균제곱은 모형의 분산을 나타내므로, 효과에 대한 평균제곱과 오차에 대한 평균제곱을 비교하여 모형이 설명하는 변동과 설명하지 못하는 잔차 사이의 상대적인 중요성을 평가하는 데 사용됩니다. 이러한 비교를 통해 각 처리나 요인이 결과에 미치는 영향을 파악하고, 모형의 적합성을 평가할 수 있습니다.
(5) 검정통계량
분산분석의 검정통계량은 아래와 같습니다.
$Y_{ij} : i$번째 그룹의 $j$번째 관측값, $i = 1,2,...,p, \quad j = 1,2,...,n$
$\bar{Y_i} : i$번째 그룹의 표본평균, $\bar{Y}:$ 전체 관측값의 평균
$$F_0=\frac{\sum_{i=1}^p n_i(\bar{Y_i}-\bar{Y})^2/(p-1)}{\sum_{i=1}^p \sum_{j=1}^{n_i}(\bar{Y_{ij}}-\bar{Y})^2/ \sum_{i=1}^p(n_i-1)} \sim F_{p-1,N-p}$$
$N = \sum_{i=1}^p n_i $ (총관측치)
위 검정 통계량은 아래와 같이 나타낼 수 있습니다.
$$F_0=\frac{SSTR/(p-1)}{SSE/(N-p)} = \frac{MSTR}{MSE} \sim F_{p-1,N-p}$$
검정통계량은 평균제곱처리를 평균제곱오차로 나눈 값이라 할 수 있습니다.
이것은 처리 효과가 크고 오차가 작을수록 각 처리 간의 평균값의 차이가 오차에 의해 기대되는 변동에 비해 상대적으로 크기 때문에 귀무가설을 기각할 가능성이 높아진다는 것을 의미합니다. 이는 검정통계량이 크고 p-value가 작아지는 경향을 보입니다. 따라서 처리 효과가 클수록 각 처리 간의 차이가 통계적으로 유의미하다는 결론을 더 강하게 내릴 수 있습니다.
3. 분산분석표
위 변동분해에 대한 내용을 정리하여 요약한 것이 분산분석표입니다.
아래는 일원배치 분산분석표입니다.
| 변동요인 | 자유도 | 제곱합 | 평균제곱 | F-통계량 |
| 처리(모형) | p-1 | SSTR | MSTR | MSTR/MSE |
| 오차 | N-p | SSE | MSE | |
| 전체 | N-1 | TSS |
'통계학 이야기' 카테고리의 다른 글
| 89. 분산분석 - 등분산성 (0) | 2024.07.04 |
|---|---|
| 88. R을 이용한 분산분석(ANOVA) (1) | 2024.07.03 |
| 85. 일원배치 분산분석(One-Way ANOVA) (1) | 2024.06.28 |
| 84. 분산분석 통계모형(Model) (0) | 2024.06.27 |
| 83. 분산분석의 검정통계량 (0) | 2024.06.26 |



