
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 이원배치 분산분석
- 이항분포
- 반복있음
- 회귀분석
- r
- 변량효과모형
- 확률
- 가설검정
- JavaScript
- 산점도
- 오블완
- 혼합효과모형
- css
- version 2
- 인공지능
- 분산분석
- 반복없음
- 고정효과모형
- version 1
- 통계학
- 변동분해
- 글쓰기
- html
- 경제학
- 해운업
- 티스토리챌린지
- 데이터 과학
- 추정
- 에세이
- 정규분포
- Today
- Total
생각 작업실 The atelier of thinking
27. R을 이용한 산점도, 공분산, 상관관계 구하기 본문
Chapter 27. R을 이용한 산점도, 공분산, 상관관계 구하기
지난 회차에 다변량의 기술통계인 산점도,공분산, 상관관계 등에 대해서 알아봤습니다.
2023.09.22 - [통계학 이야기] - 26. 다변량 자료의 기술 통계 - 공분산, 상관관계 & 산점도
26. 다변량 자료의 기술 통계 - 공분산, 상관관계 & 산점도
Chapter 26. 다변량 자료의 기술통계 앞서 다변량 변수(자료) 형태는 아래와 같이 나눠봤습니다. 경우 X Y (1) 범주형 자료 범주형 자료 (2) 범주형 자료 수치형 자료 (3) 수치형 자료 범주형 자료 (4) 수
thinking-atelier.tistory.com
지난 회차에 올림픽 100미터 우승 기록에 대한 산점도를 그려봤었습니다. 이번에는 R을 이용하여 남녀 구분한 산점도와 공분산, 상관관계를 구해보겠습니다.
1. 자료불러오기
olympic <- read.csv("100m.csv", header = TRUE, fileEncoding = "CP949", encoding = "UTF-8")
head(olympic) year record gender
1 1896 12.0 M
2 1900 11.0 M
3 1904 11.0 M
4 1908 10.8 M
5 1912 10.8 M
6 1920 10.8 M
◈ 예제 : 올림픽 100미터 우승 기록
| 연도 | 우승기록 | 연도 | 우승기록 | 연도 | 우승기록 | |||
| 남자 | 여자 | 남자 | 여자 | 남자 | 여자 | |||
| 1896 | 12 | - | 1936 | 10.3 | 11.5 | 1988 | 9.92 | 10.54 |
| 1900 | 11 | - | 1948 | 10.3 | 11.9 | 1992 | 9.96 | 10.82 |
| 1904 | 11 | - | 1952 | 10.4 | 11.5 | 1996 | 9.84 | 10.94 |
| 1908 | 10.8 | - | 1956 | 10.5 | 11.5 | 2000 | 9.87 | 10.75 |
| 1912 | 10.8 | - | 1960 | 10.2 | 11.0 | 2004 | 9.85 | 10.93 |
| 1920 | 10.8 | - | 1964 | 10.0 | 11.4 | 2008 | 9.69 | 10.78 |
| 1924 | 10.6 | - | 1968 | 9.9 | 11.0 | 2012 | 9.63 | 10.75 |
| 1928 | 10.8 | 12.2 | 1976 | 10.14 | 11.07 | 2016 | 9.81 | 10.71 |
| 1932 | 10.3 | 11.9 | 1984 | 10.06 | 10.97 | |||
2. 산점도 그리기
(1) 전체 자료 기준(남녀구분없이)
▶ plot( ) 함수
산점도, 선 그래프, 막대 그래프 등 다양한 종류의 그래프를 생성하는 함수입니다.
plot(x,y, type='p', col =' ', pch= , xlab=' ', ylab= ' ', main= ' ')
x : x 축에 사용할 데이터
y : y 축에 사용할 데이터
type : 그래프의 유형을 지정합니다. "p"는 산점도(점그래프), "l"은 선그래프, "b"는 선과 점을 함께 표시
pch : 점의 모양을 지정합니다.숫자나 문자로 설정합니다.
xlab : x축 이름
ylab : y축 이름
main : 그래프 이름
plot(olympic$year,olympic$record,xlab = '연도', ylab = '기록(초)',col='blue',pch=16)
※ 참고 : pch 종류(1~25)

(2) 남녀 데이터 분리
남녀 데이터를 구분하여 산점도를 그려보겠습니다.
먼저, 남녀별 데이터를 구분하여 추출해야 합니다. 이 때 유용한 함수가 subset( ) 함수입니다.
subset( ) 함수는 데이터 프레임에서 특정 조건을 만족하는 행들만 추출하는 데 사용합니다.
subset(data, condition)
data : 전체데이터
condition : 추출하고자 하는 조건
male <- subset(olympic, gender=="M")
female <- subset(olympic, gender=="F")
head(male)
head(female)> head(male)
year record gender
1 1896 12.0 M
2 1900 11.0 M
3 1904 11.0 M
4 1908 10.8 M
5 1912 10.8 M
6 1920 10.8 M> head(female)
year record gender
29 1928 12.2 F
30 1932 11.9 F
31 1936 11.5 F
32 1948 11.9 F
33 1952 11.5 F
34 1956 11.5 F
위 코드는 olympic 데이터에서 남자 데이터는 male로 여자 데이터는 female로 추출하여 저장하였습니다.
아래 코드는 각 데이터를 산점도로 표현하는 것입니다.
plot(male$year,male$record, xlab='연도',ylab = '기록(초)',col='blue',pch=16)
points(female$year,female$record,col='red',pch=16)
legend("topright",legend=c("남자","여자"),pch=c(16,16),col=c('blue',"red"),
bty="n",cex=1.2)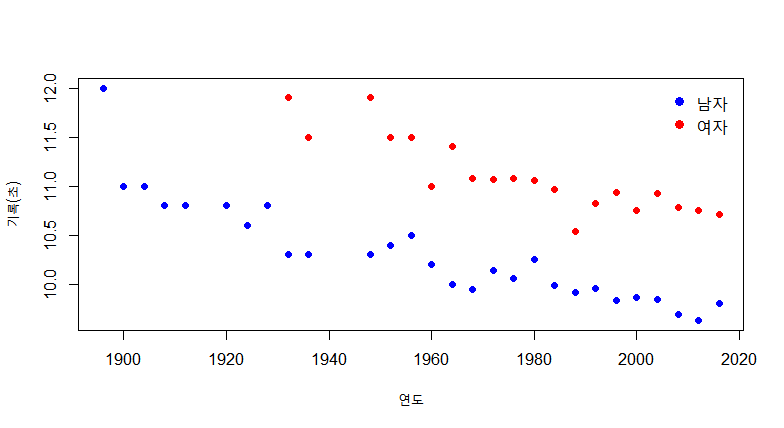
▶ points( ) 함수
이 함수는 이미 plot 함수로 생성된 그래프에 포인트 그래프를 추가할 때 사용합니다. 여러 개의 그래프를 하나의 그래프로 합칠 때 주로 사용합니다.
▶ legend( ) 함수
범례를 추가할 때 사용합니다. 위치에 관련된 매개변수를 사용하고, 나머지는 그래프의 내용과 일치하게끔 작성하면 됩니다.
3. 공분산 (Covariance)
공분산을 구하는 산식은 다음과 같습니다.
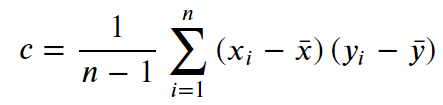
공분산을 구하는 cov( ) 함수에 구하고자 하는 두 변수를 차례로 넣어주면 됩니다.
아래는 연도와 남자 기록, 연도와 여자 기록의 공분산을 구한 것 입니다.
(1) 남자
with(male,cov(year,record))
cov(male$year,male$record)[1] -17.50646
(2) 여자
with(female,cov(year,record))
cov(female$year,female$record)[1] -10.57286
4. 상관계수(Correlation Coefficient)
상관계수를 구하는 산식은 아래와 같습니다.
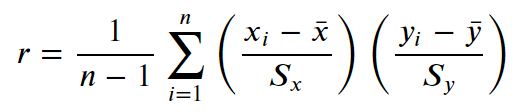
상관계수을 구하는 cor( ) 함수에 구하고자 하는 두 변수를 차례로 넣어주면 됩니다.
아래는 연도와 남자 기록, 연도와 여자 기록의 상관계수를 구한 것 입니다.
(1) 남자
with(male,cor(year,record))
cor(male$year,male$record)[1] -0.9013949(2) 여자
with(female,cor(year,record))
cor(female$year,female$record)[1] -0.8915346
정리
# 1. 자료 불러오기
olympic <- read.csv("100m.csv", header = TRUE, fileEncoding = "CP949", encoding = "UTF-8")
head(olympic)
# 2. 산점도
plot(olympic$year,olympic$record,xlab = '연도',
ylab = '기록(초)',col='blue',pch=16)
# 3. 데이터 분리
male <- subset(olympic, gender=="M")
female <- subset(olympic, gender=="F")
head(male)
head(female)
plot(male$year,male$record, xlab='연도',ylab = '기록(초)',col='blue',pch=16)
points(female$year,female$record,col='red',pch=16)
legend("topright",legend=c("남자","여자"),pch=c(16,16),col=c('blue',"red"),
bty="n",cex=1.2)
# 4. 공분산
with(male,cov(year,record))
cov(male$year,male$record)
with(female,cov(year,record))
cov(female$year,female$record)
# 5. 상관관계
with(male,cor(year,record))
cor(male$year,male$record)
with(female,cor(year,record))
cor(female$year,female$record)'통계학 이야기' 카테고리의 다른 글
| 29. 확률의 공리와 기본 정리 (1) | 2023.09.27 |
|---|---|
| 28. 확률과 통계 (0) | 2023.09.26 |
| 26. 다변량 자료의 기술 통계 - 공분산, 상관관계 & 산점도 (0) | 2023.09.22 |
| 25. R을 이용한 범주형 자료 요약 (1) | 2023.09.21 |
| 24. 범주형 자료 요약 (0) | 2023.09.21 |



